#include <sys/types.h>
#include <grp.h>
struct group *getgrname(const char *name);
struct group *getgrgid(gid_t gid);
struct group *getgrent(void);
void setgrent(void);
void endgrent(void);
사용자 뿐만 아니라 그룹에 대한 정보도 가져올 수 있다.
위와 비슷하고 그룹이란 것만 변경이 되었기 때문에 바로 실습으로 가보도록 하겠다.
group의 구조체는 아래와 같다.
struct group {
char *gr_name; /* [XBD] group name */
char *gr_passwd; /* [???] group password */
gid_t gr_gid; /* [XBD] group id */
char **gr_mem; /* [XBD] group members */
};
그룹에 대한 정보를 읽어오는 프로그램을 만들어보자.
#include <stdio.h>
#include <stdlib.h>
#include <grp.h>
int main(void){
struct group *grp;
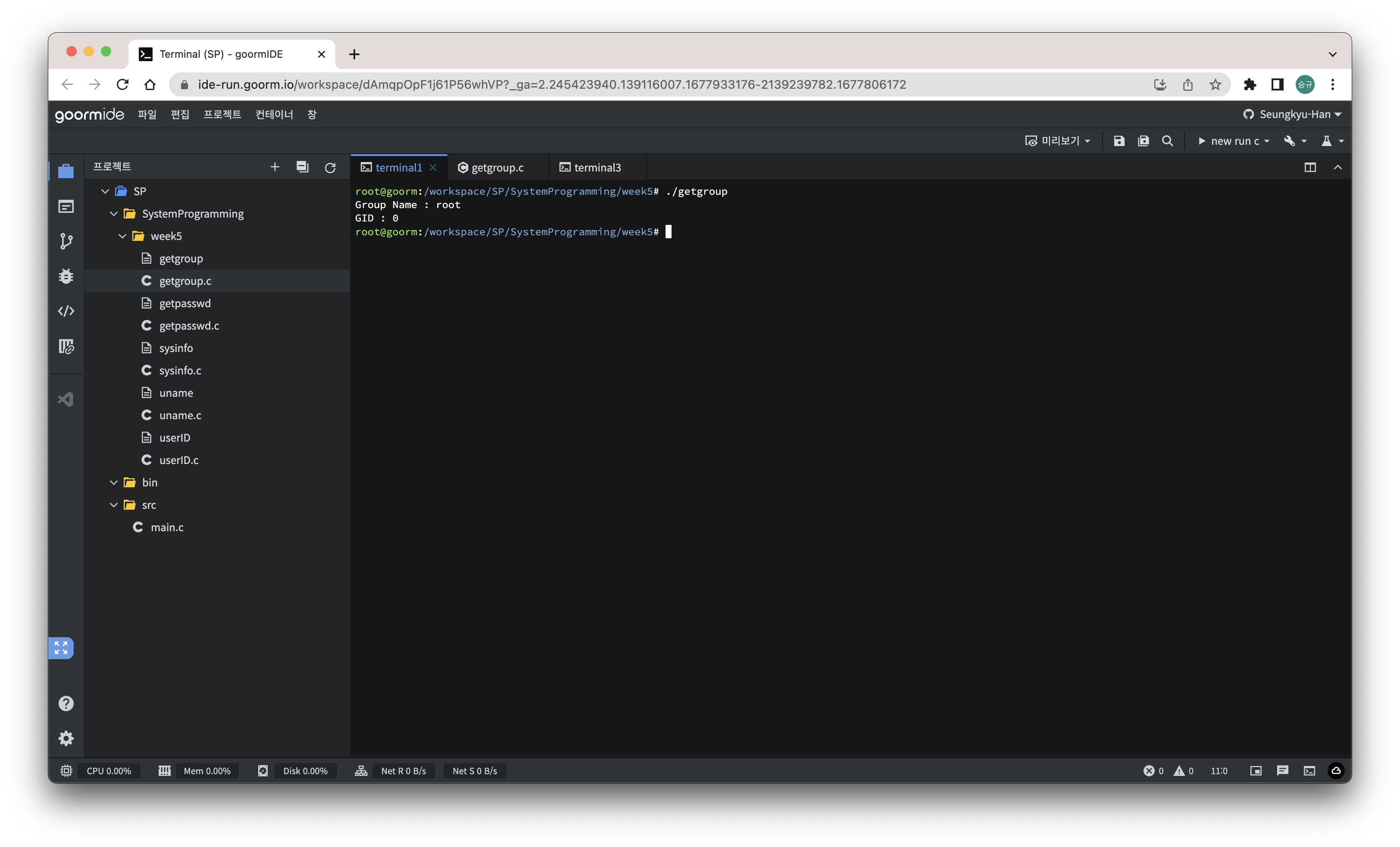
grp = getgrnam("root");
printf("Group Name : %s\n", grp->gr_name);
printf("GID : %d\n", (int)grp->gr_gid);
return 0;
}
그룹의 이름을 이용해 정보를 가져왔다.
시간 정보
리눅스의 시간은 1970년 1월 1일 0시 0분 0초를 기준으로 흘러가며 현재까지 경과한 시간을 초 단위로 저장한다.
Getting time
#include <sys/time.h>
time_t time(time_t *tloc);
-tloc
얻어올 초를 저장할 주소
return: 얻어온 초, -1(error)
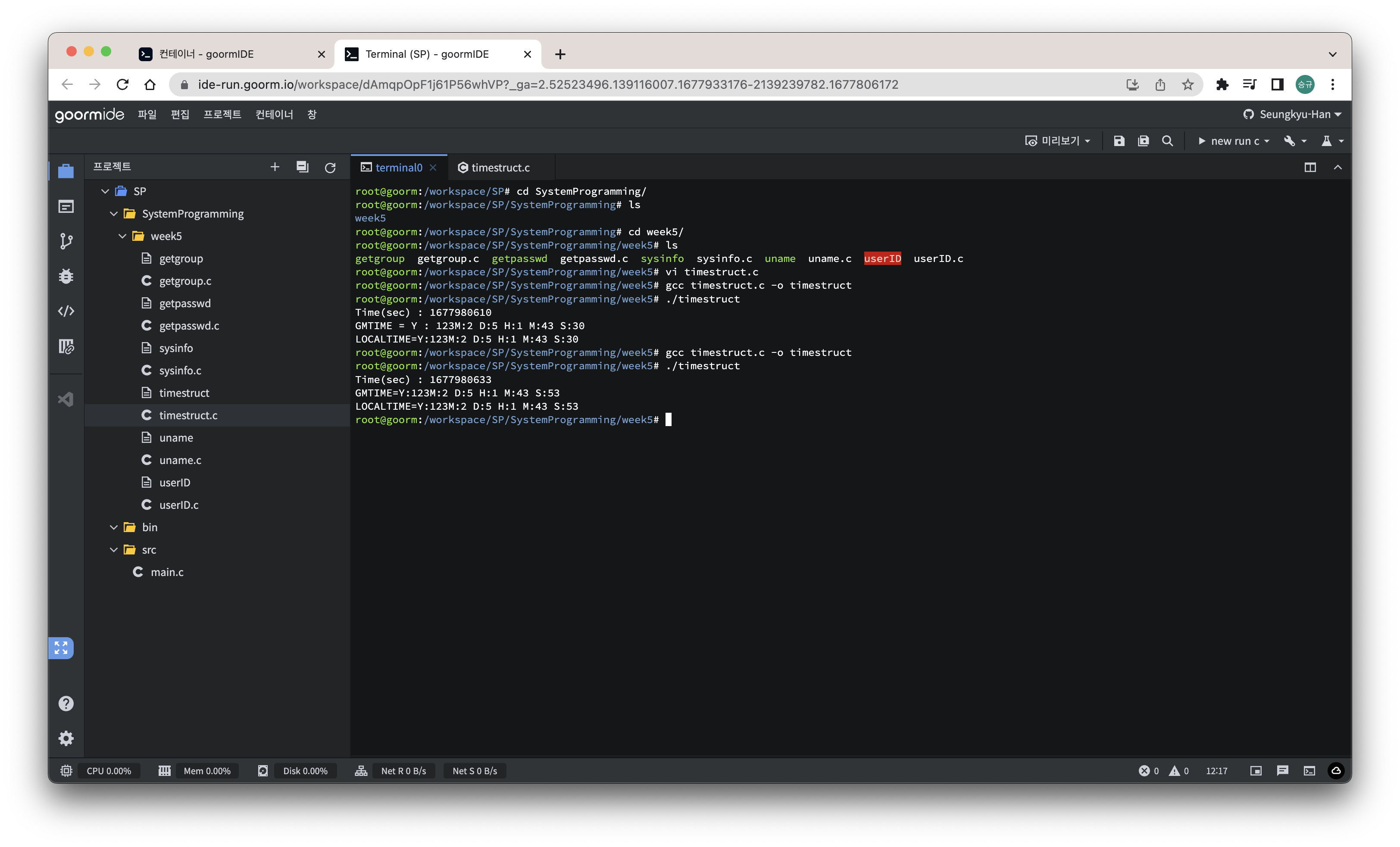
하지만 이렇게 얻어온 시간은 흘러간 초로 표현이 되기 때문에 읽기가 매우 힘들다.
그래서 이 time_t를 우리가 보기 편한 시간으로 보여주는 함수가 있고 그 시간을 저장하는 구조체가 있다.
우선 해당 구조체부터 살펴보자면
struct tm {
int tm_sec; /* seconds after the minute [0-60] */
int tm_min; /* minutes after the hour [0-59] */
int tm_hour; /* hours since midnight [0-23] */
int tm_mday; /* day of the month [1-31] */
int tm_mon; /* months since January [0-11] */
int tm_year; /* years since 1900 */
int tm_wday; /* days since Sunday [0-6] */
int tm_yday; /* days since January 1 [0-365] */
int tm_isdst; /* Daylight Savings Time flag */
};
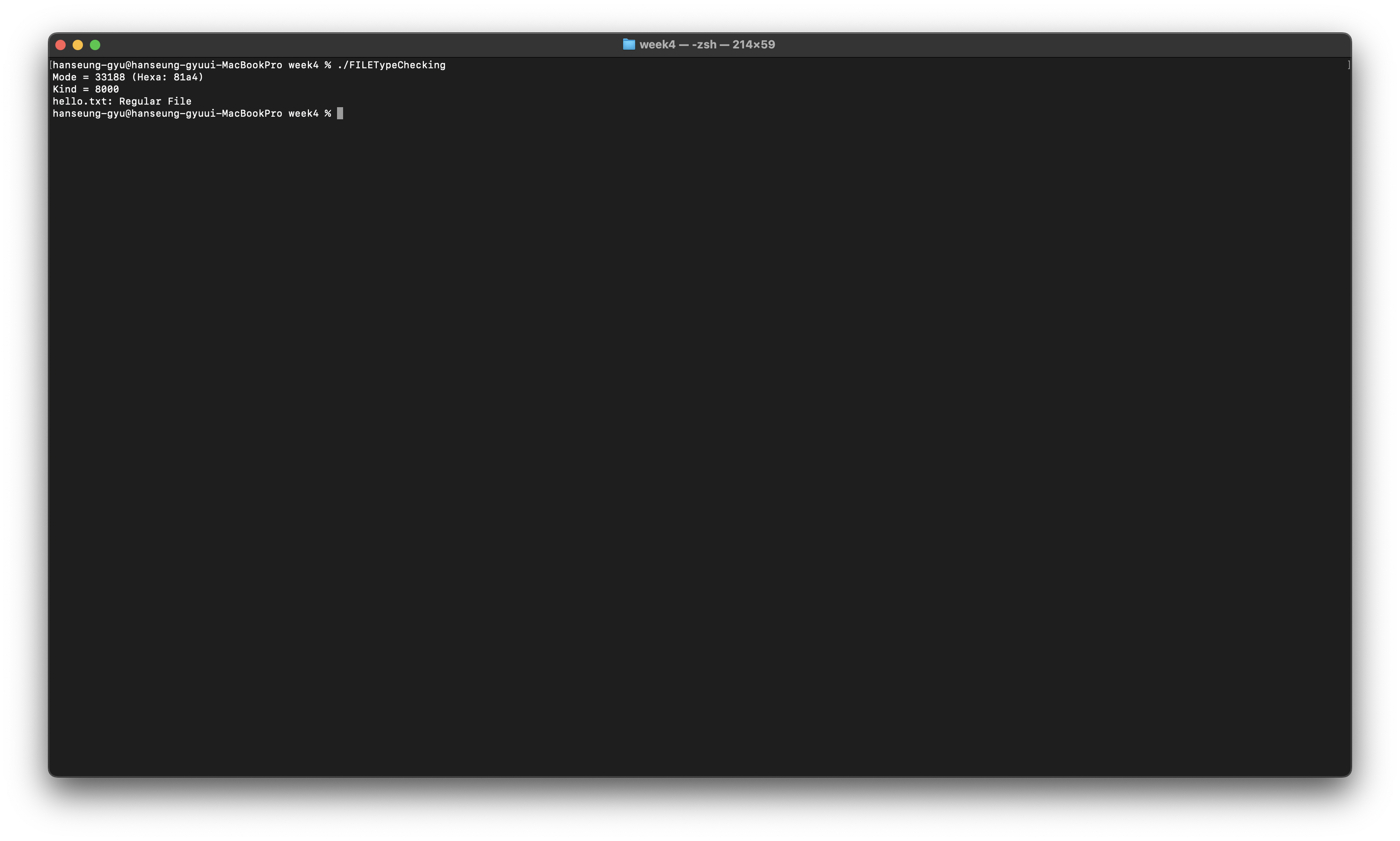
리눅스는 모두 파일로 저장이 되고 종류로는 Regular file, Special file, Directory, Symbolic link file... 등이 있다.
파일의 종류를 확인하고 싶으면 ls -l 명령어를 사용하면 된다.
정보 가장 앞에 나온 문자로 확인을 한다.
문자
파일의 종류
-
일반 파일
d
디렉토리
b
블록 장치 특수 파일
c
문자 장치 특수 파일
l
심볼릭 링크
Types of file
- Special file
장치와 데이터를 주고 받는 통로이다, 데이터 블록이 없으며 장치 번호를 inode에 저장한다.
단위에 따라 Character device file, Block device file로 나뉜다.
- Regular file
Text or binary data file이다.
- Directory(윈도우의 파일)
파일의 목록을 저장한 파일이다.
- Symbolic link file
이미 존재하는 파일이나 디렉토리에 접근 할 수 있는 새로운 이름이다.
File organization
파일을 구성하는 요소는 3가지이다.
- File name
파일의 이름으로 사용자가 파일에 접근할 때 사용한다.
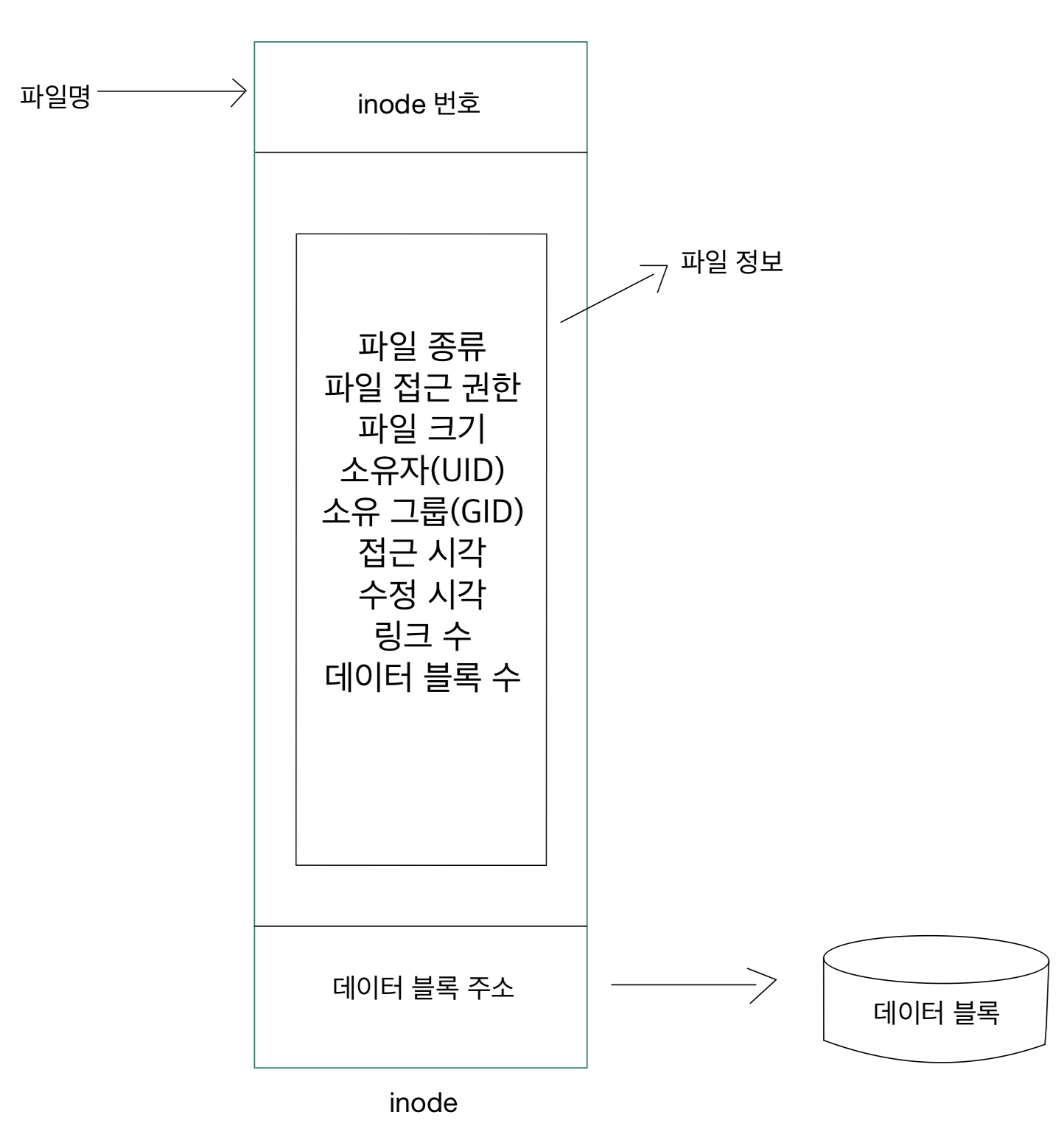
- inode
파일에 대한 정보를 저장한다, 번호를 통해 관리/접근 한다.
- Data block
실제 데이터가 저장된 디스크의 공간이다.
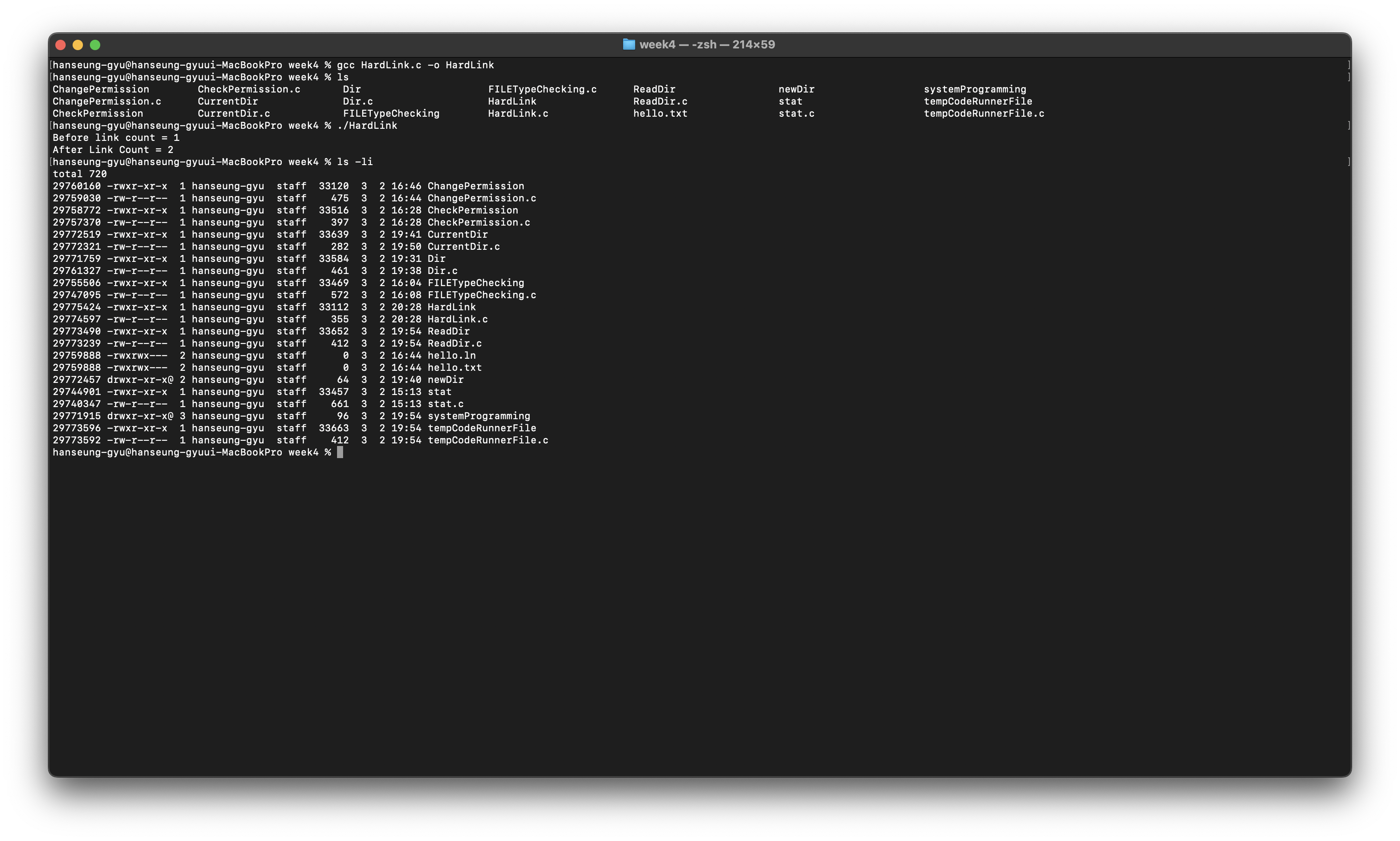
inode는 ls -i로 확인할 수 있다.
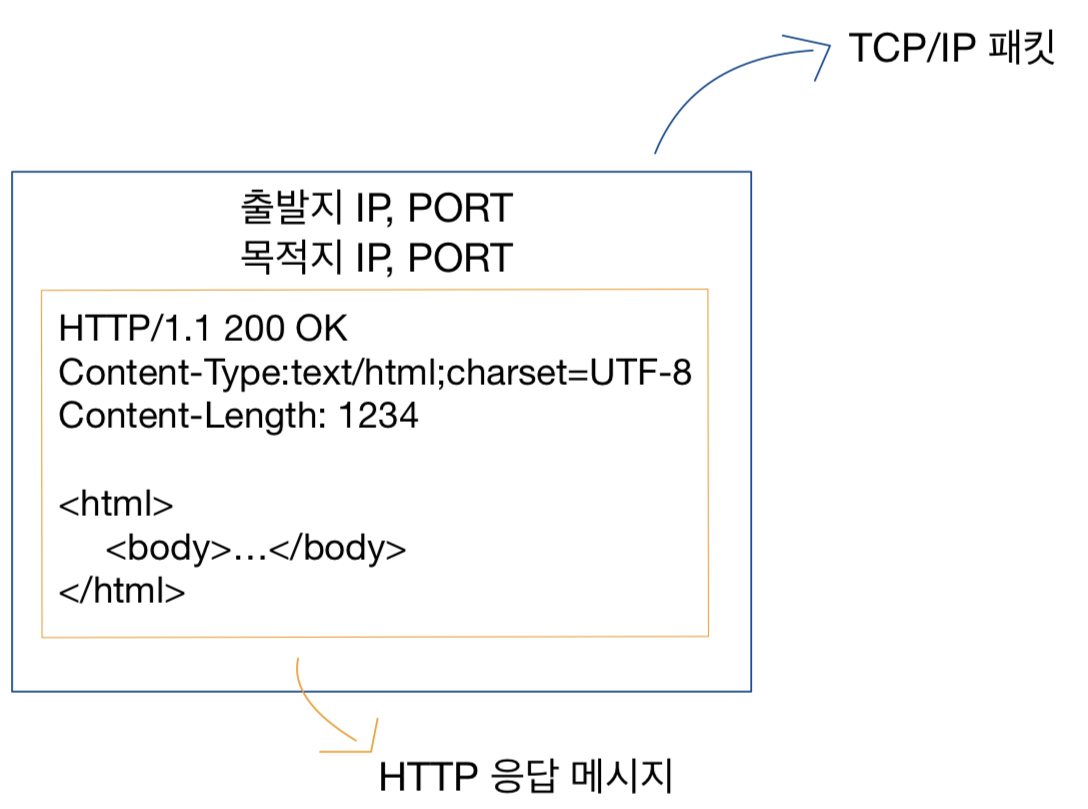
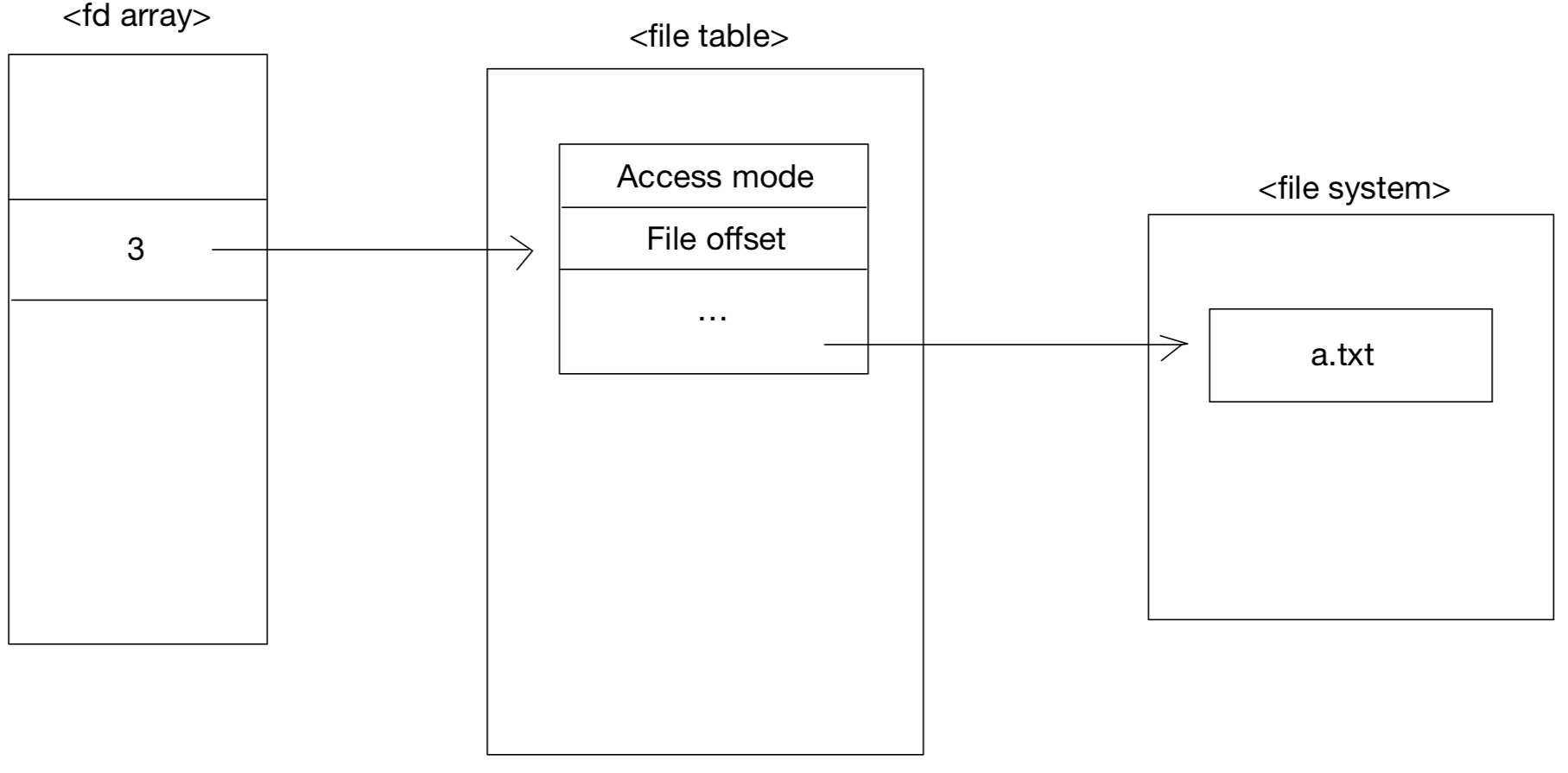
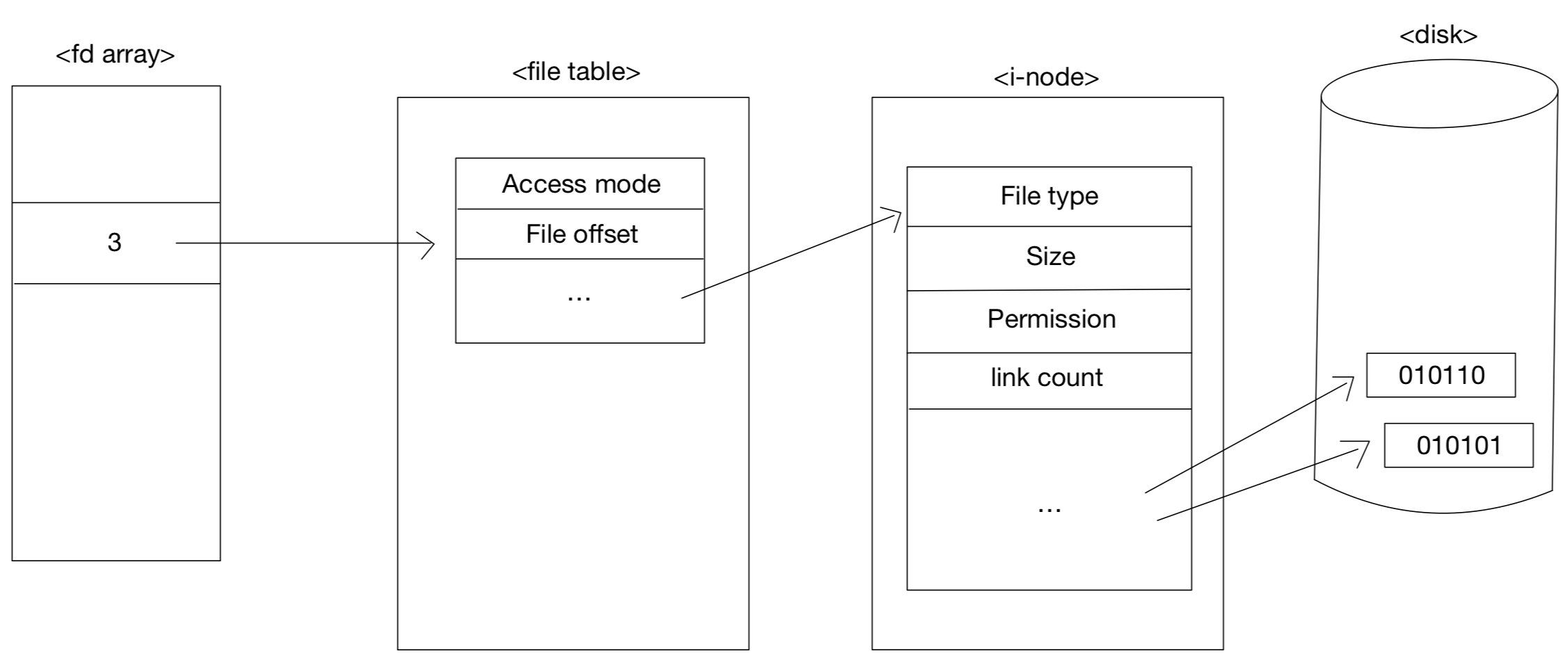
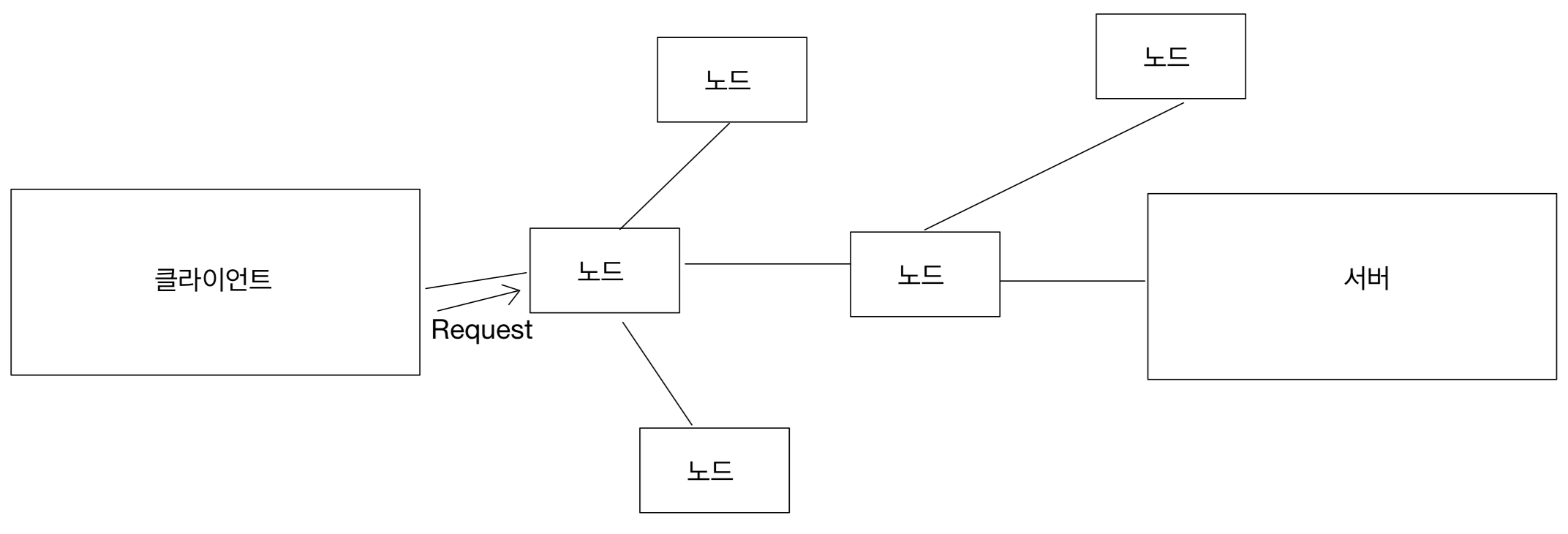
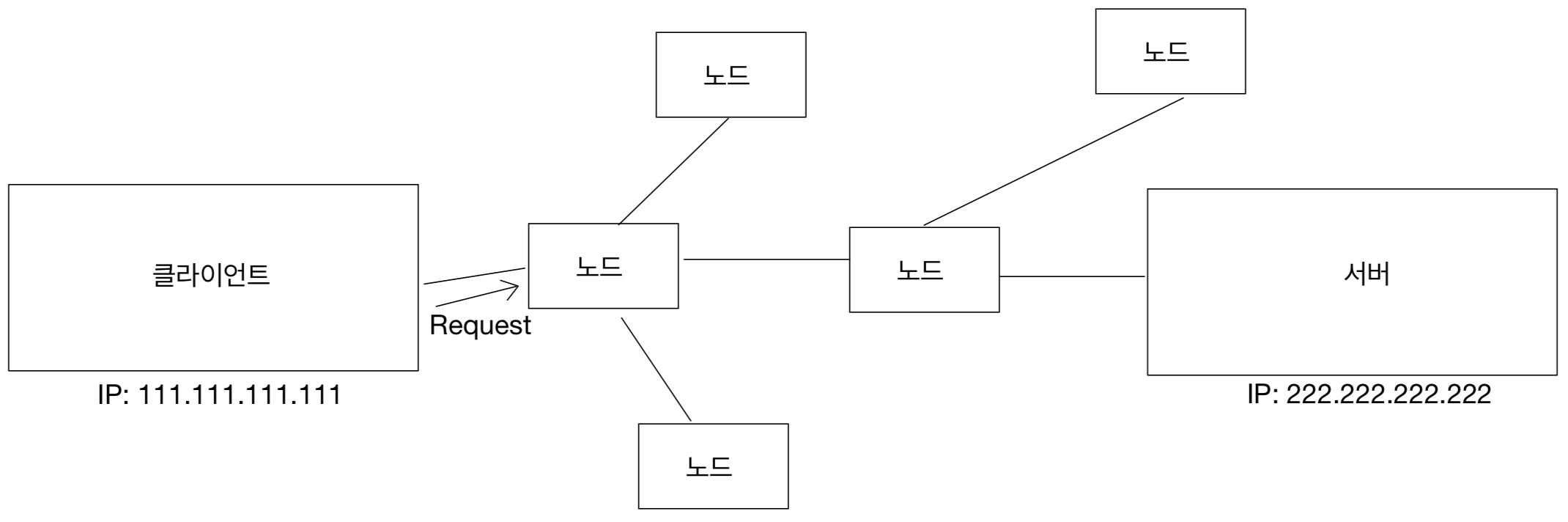
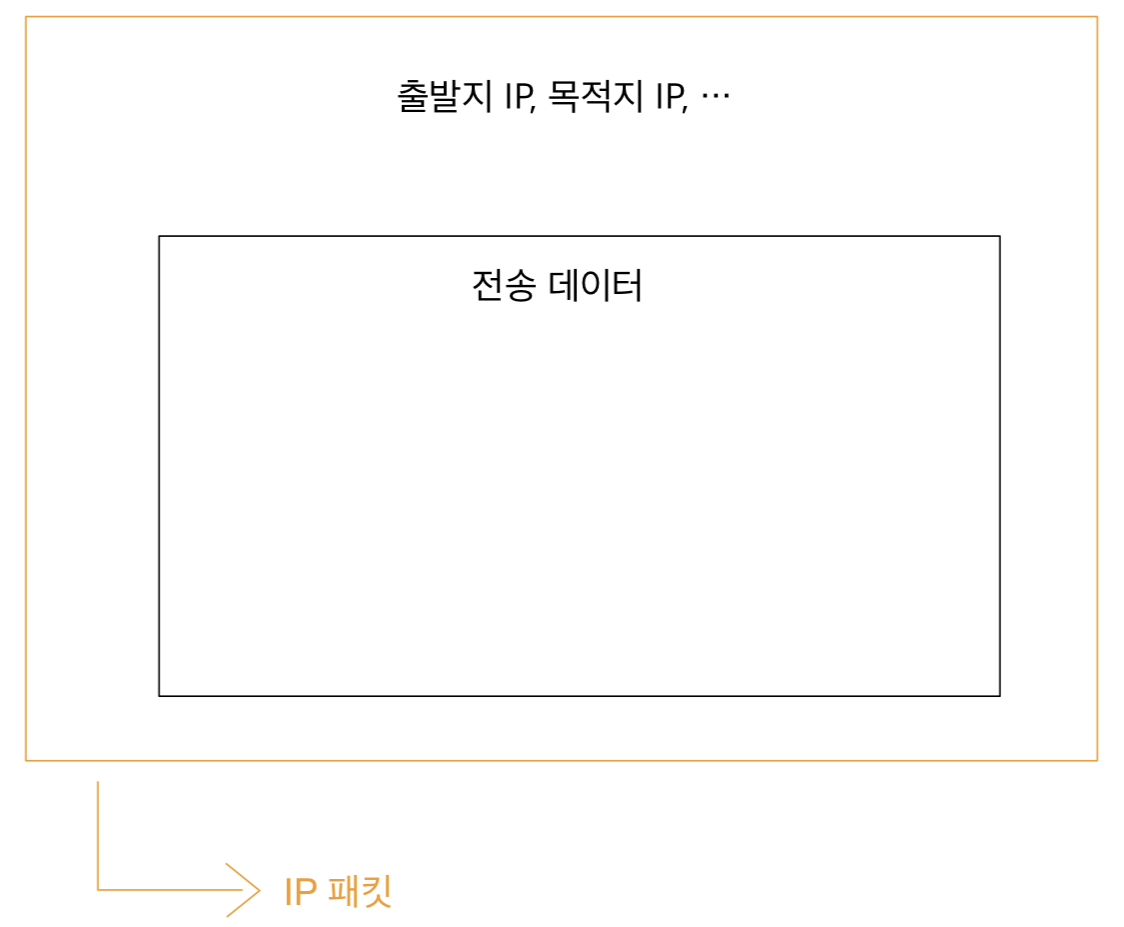
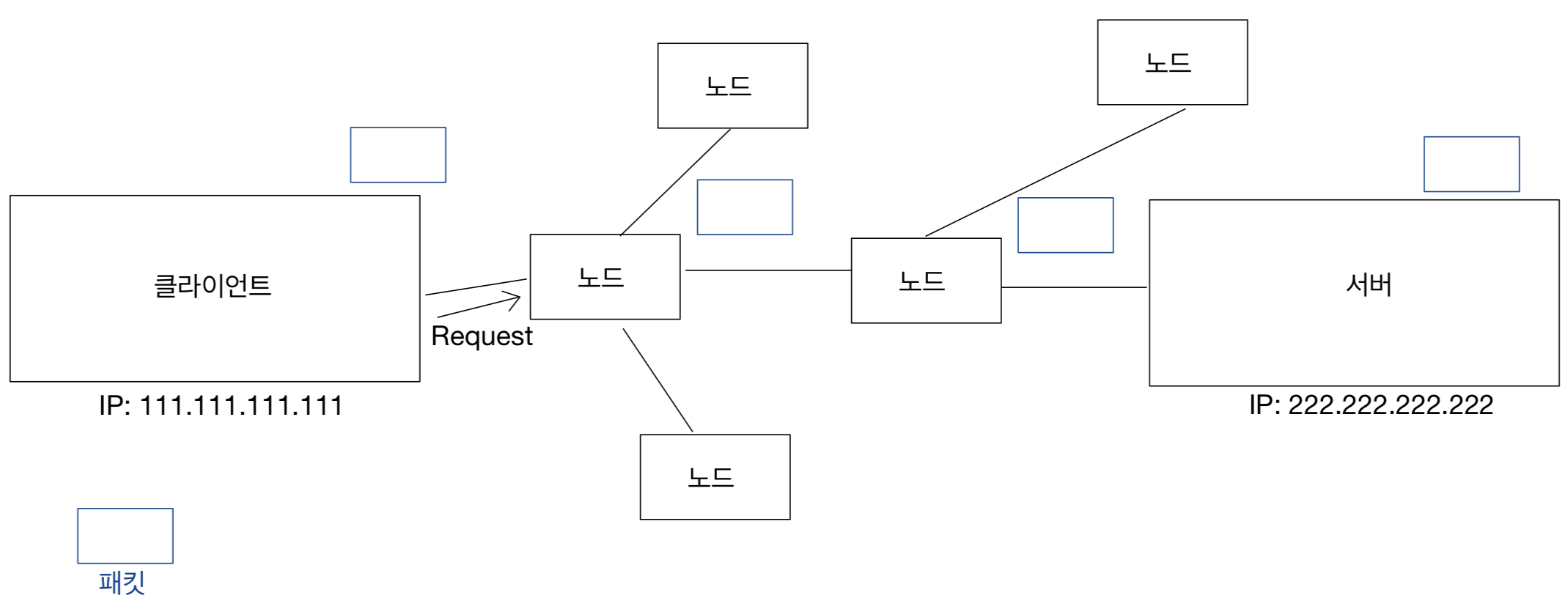
2주차에서 보았던 file table을 다시 보자면
file table은 직접 해당 파일을 가리키는 것이 아니라
i-node를 가리키고 inode에서 해당 파일을 가리키는 것이다.
시스템 콜을 사용을 해서 i-node에 저장되어 있는 파일 정보를 읽어 올 수 있다.
File information
#include <fcntl.h>
#include <sys/types.h>
#include <sys/stat.h>
int stat(const char *pathname, struct stat *buf);
int fstat(int fd, struct stat *buf);
file descriptor를 사용하면 fstat를 사용한다.
- pathname(file path or file descriptor)
파일의 경로(파일의 이름을 포함한)
-buf
파일의 정보를 저장한 주소
return: 0(success), -1(error)
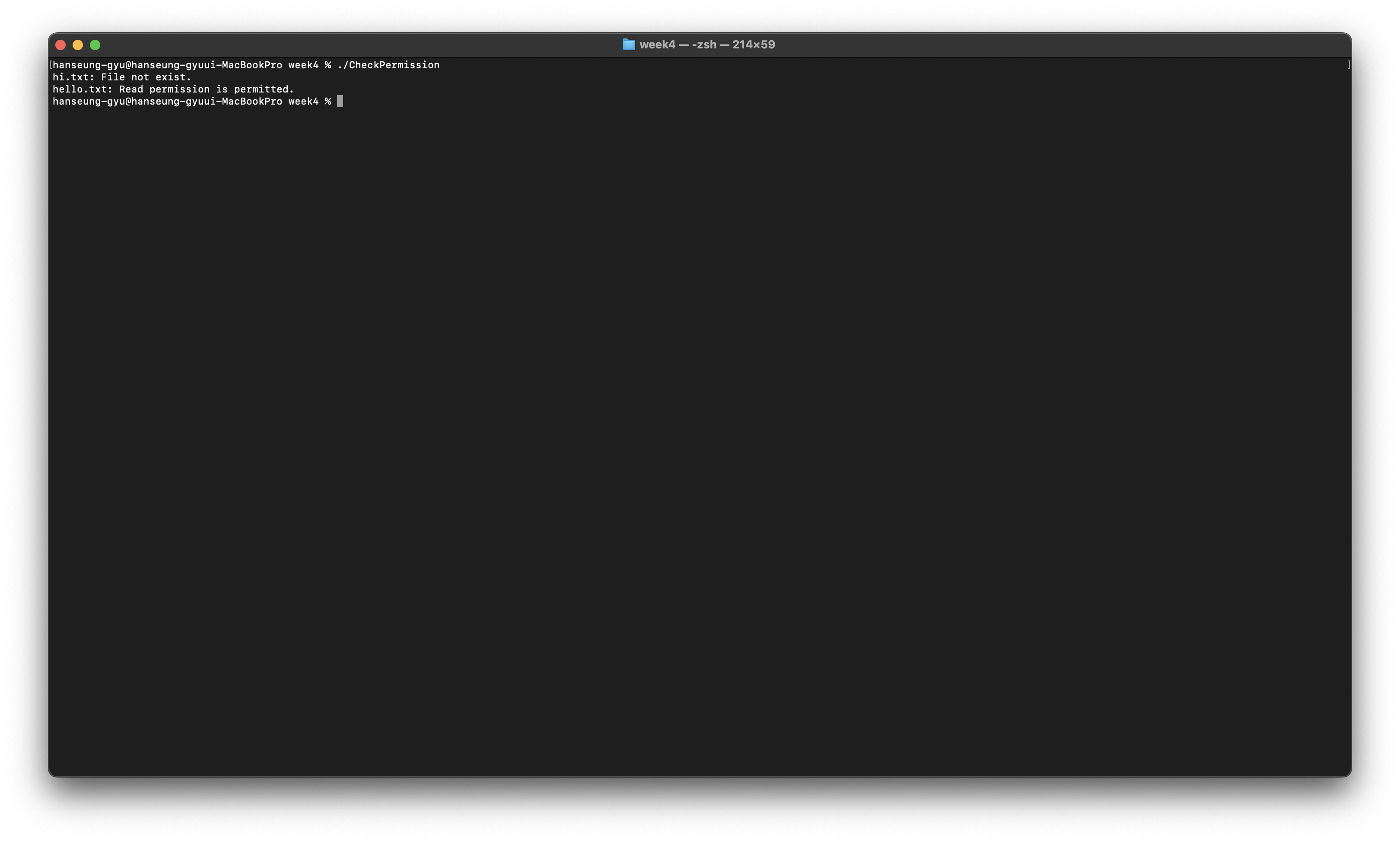
당연히 파일에 읽기 권한이 있어야 한다.
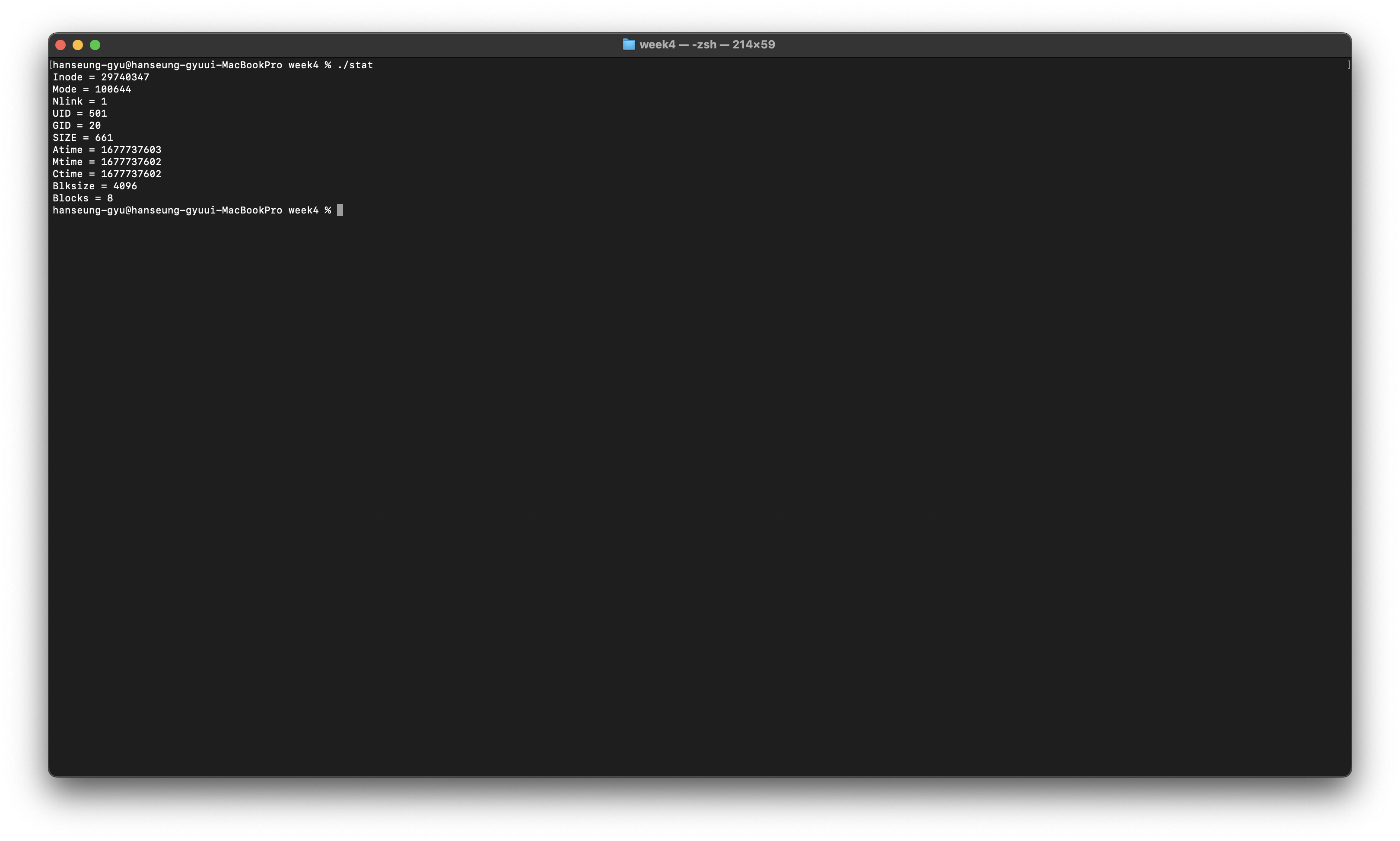
struct stat의 구조체를 살펴보면
struct stat {
dev_t st_dev; /* [XSI] ID of device containing file */
ino_t st_ino; /* [XSI] File serial number */
mode_t st_mode; /* [XSI] Mode of file (see below) */
nlink_t st_nlink; /* [XSI] Number of hard links */
uid_t st_uid; /* [XSI] User ID of the file */
gid_t st_gid; /* [XSI] Group ID of the file */
dev_t st_rdev; /* [XSI] Device ID */
time_t st_atime; /* [XSI] Time of last access */
long st_atimensec; /* nsec of last access */
time_t st_mtime; /* [XSI] Last data modification time */
long st_mtimensec; /* last data modification nsec */
time_t st_ctime; /* [XSI] Time of last status change */
long st_ctimensec; /* nsec of last status change */
off_t st_size; /* [XSI] file size, in bytes */
blkcnt_t st_blocks; /* [XSI] blocks allocated for file */
blksize_t st_blksize; /* [XSI] optimal blocksize for I/O */
__uint32_t st_flags; /* user defined flags for file */
__uint32_t st_gen; /* file generation number */
__int32_t st_lspare; /* RESERVED: DO NOT USE! */
__int64_t st_qspare[2]; /* RESERVED: DO NOT USE! */
};