728x90
이번엔 List이다.
문제에 관련된 DB가 있다고 하자.
테이블은
| question | |
| id | varchar(10) |
| text | varchar(20) |
| question_choice | |
| question_id | varchar(10) |
| idx | integer(10) |
| text | varchar(20) |
그러면 question안에 객관식 보기인 question_choice들이 순서대로 들어가 있어야 할 것이다.
이런 경우에는 순서가 존재하기 때문에 저번에 사용한 Set을 사용할 수 없고, List를 사용해야 한다.
import jakarta.persistence.*;
import java.util.List;
@Entity
@Table(name = "question")
public class question {
@Id
private String id;
private String text;
@ElementCollection
@CollectionTable(
name = "question_choice",
joinColumns = @JoinColumn(name = "question_id")
)
@OrderColumn(name = "idx")
@Column(name = "text")
private List<String> choices;
protected question () {}
public question(String id, String text, List<String> choices) {
this.id = id;
this.text = text;
this.choices = choices;
}
//getter... settter
}import jakarta.persistence.EntityManager;
import jakarta.persistence.EntityManagerFactory;
import jakarta.persistence.EntityTransaction;
import jakarta.persistence.Persistence;
import java.util.List;
public class questionMain {
public static void main(String[] args) {
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("jpabegin");
EntityManager entityManager = entityManagerFactory.createEntityManager();
EntityTransaction entityTransaction = entityManager.getTransaction();
try{
entityTransaction.begin();
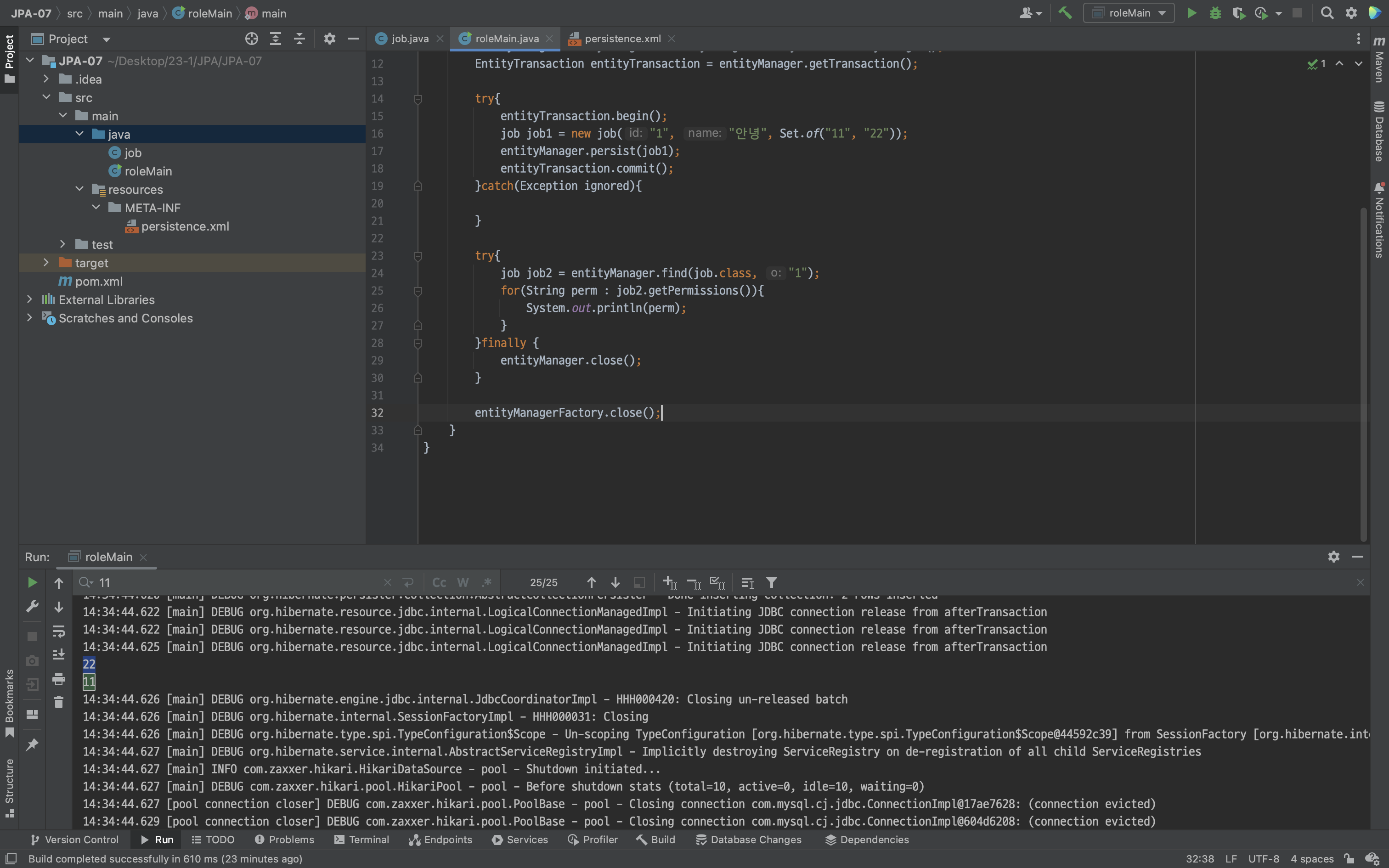
question question1 = new question("1", "문제1", List.of("1번", "2번", "3번", "4번", "5번"));
entityManager.persist(question1);
entityTransaction.commit();
}catch (Exception ignored){
}
try{
question question2 = entityManager.find(question.class,"1");
for(String choice : question2.getChoices()){
System.out.println(choice);
}
}finally {
entityManager.close();
}
entityManagerFactory.close();
}
}이렇게 Set과 똑같이 작성하지만, @OrderColumn을 추가해준다.

당연히 @Embedded도 사용이 가능하다.
import jakarta.persistence.Embeddable;
@Embeddable
public class choice {
private String text;
private boolean input;
protected choice() {}
public choice(String text, boolean input) {
this.text = text;
this.input = input;
}
//getter... setter...
}import jakarta.persistence.*;
import java.util.List;
@Entity
@Table(name = "question")
public class question2 {
@Id
private String id;
private String text;
@ElementCollection
@CollectionTable(
name = "question_choice",
joinColumns = @JoinColumn(name = "question_id")
)
@OrderColumn(name = "idx")
private List<choice> choiceList;
protected question2 (){}
public question2(String id, String text, List<choice> choiceList) {
this.id = id;
this.text = text;
this.choiceList = choiceList;
}
//getter... setter...
}import jakarta.persistence.EntityManager;
import jakarta.persistence.EntityManagerFactory;
import jakarta.persistence.EntityTransaction;
import jakarta.persistence.Persistence;
import java.util.List;
public class questionMain2 {
public static void main(String[] args) {
EntityManagerFactory entityManagerFactory = Persistence.createEntityManagerFactory("jpabegin");
EntityManager entityManager = entityManagerFactory.createEntityManager();
EntityTransaction entityTransaction = entityManager.getTransaction();
try{
entityTransaction.begin();
question2 question1 = new question2("1", "문제1", List.of(new choice("1", false),
new choice("2", true)));
entityManager.persist(question1);
entityTransaction.commit();
}catch (Exception ignored){
}
try{
question2 question2 = entityManager.find(question2.class,"1");
for(choice choice : question2.getChoiceList()){
System.out.println(choice.getInput() + ", " + choice.getText());
}
}finally {
entityManager.close();
}
entityManagerFactory.close();
}
}'Spring > JPA' 카테고리의 다른 글
| JPA 10장 (영속 컨텍스트와 LifeCycle) (0) | 2023.03.22 |
|---|---|
| JPA 9장 (Map collection mapping) (0) | 2023.03.21 |
| JPA 7장 (Set collection mapping) (0) | 2023.03.18 |
| JPA 6장 (@Embeddable) (0) | 2023.03.17 |
| JPA 5장 (Entity 식별자 생성 방식) (0) | 2023.03.16 |