컨트롤러는 사용자로부터 온 특정한 요청을 어디로 보낼 것인지에 대한 목적으로 만들어졌다. 라우팅 메커니즘은 어떤 컨트롤러가 각각의 요청을 받을 것인지를 결정한다. 종종, 컨트롤러는 여러개의 라우트를 가지며, 그 각각의 라우트는 다른 동작을 수행한다.
컨트롤러를 만들기 위해서, 우리는 클래스와 데코레이터를 사용한다. 데코레이터는 해당 클래스의 메타 정보를 통해, Nest가 일치하는 응답을 라우팅 해 줄 수 있도록 도와준다.
Routing
예시에서 우리는 기본적인 컨트롤러를 만들기 위해 필요한 @Controller() 데코레이터를 사용할 것이다. cats라는 접두사를 가진 경로를 명시하며, @Controller에 접두사를 작성하는 것은 이후에 추가적으로 해당 경로를 더 명시할 필요없이 그룹화 할 수 있도록 도와준다. 예를 들어 우리가 Cats와 상호작용하는 라우트를 만들고 싶다면, 해당 경로의 접두사는 /cats가 될 것이며, @Controller('cats')로 작성하면 이 경로들을 그룹화 해주는 것이다. 그렇기에 컨트롤러에 추가할 라우트들에 'cats를 반복해서 작성 할 필요가 없다.
import { Controller, Get } from '@nestjs/common';
@Controller('cats')
export class CatsController {
@Get()
findAll(): string {
return 'This action returns all cats';
}
}
@Get()이라는 Http 요청 데코레이터는 findAll()이라는 메서드 이름 앞에 위치하며, Nest가 특정 경로에 대한 라우트를 생성하도록 한다. 이제 이 route path는 controller에 이미 명시해둔 경로와 메서드에 작성한 데코레이터의 경로를 조합하여 만들어진다. 여기에서는 @Get()에 경로 명시가 없기 때문에 /cats로 들어오는 @Get() 요청에 대해 동작하는 것이다.
위의 예시에서 해당 경로로 Get 요청이 들어온다면, Nest는 라우트하여 findAll() 메서드를 호출한다. 여기서 메서드의 이름은 임시이며, Nest는 이 컨트롤러의 메서드 이름에 의미를 부여하지 않는다.
해당 메서드는 아마 200 status code를 리턴할 것이다, 저기 작성해둔 문자열과 함께 말이다. 이것에 대해 설명하기 위해서는 2가지의 응답을 바꾸는 방법에 대해 알아야 한다.
standard (recommended)
해당 내장 메서드를 이용하면, Javascript가 객체 혹은 배열을 리턴 할 때, Json으로 자동 변환되어 돌려주게 된다. 하지만 만약 Javascript의 원시타입(string, number..)만 응답한다면, 직렬화를 시도하지 않는다.
Library-specific
만약 @Res()로 사용하는 response object와 관련된 라이브러리를 사용할 수 있다. 이것을 사용하면, 개발자는 response.status(200).send()과 같이 작성해서 객체를 응답 할 수 있다.
Request object
핸들러는 종종 클라이언트에서 보낸 요청의 세부 정보를 알아와야 할 때가 있다. Nest는 이런 요청 객체에 대한 접근을 허용한다. 개발자는 @Req() 데코레이터를 사용하여 사용자가 보낸 요청의 객체에 접근이 가능하다.
import { Controller, Get, Req } from '@nestjs/common';
import { Request } from 'express';
@Controller('cats')
export class CatsController {
@Get()
findAll(@Req() request: Request): string {
console.log(request);
return 'This action returns all cats';
}
}
위와 같은 코드로 request를 출력해보니,
이런식으로 긴데이터가 들어왔던 것을 볼 수 있었다.
이렇게 많은 데이터에서 원하는 속성을 찾아서 가져오기는 힘들 것 같고, @Body()와 @Query()같은 전용 데코레이터가 있기에 이것들을 사용해서 객체에 접근하게 될 것이다.
아래는 각각의 데코레이터들이 어떤것과 대응되는지를 보여주는 표이다.
@Request(), @Req()
req
@Response(), @Res()
res
@Next()
next
@Session()
req.session
@Param(key?: string)
req.params/req.params[key]
@Body(key?: string)
req.body/req.body[key]
@Query(key?: string)
req.query/req.query[key]
@Headers(name?: string)
req.headers/req.headers[name]
@Ip()
req.ip
@HostParam()
req.hosts
만약 @Res()나 @Response()를 사용하면, Nest에서 해당 핸들러가 응답까지 알아서 처리한다고 생각하고 끝까지 처리해주지 않는다.
그렇기에 해당 데코레이터를 사용하면 응답까지 개발자가 완성해서 리턴해줘야 한다.
Resources
이전에 cats의 GET API를 만들어보았다. 이번에는 POST를 통해 새로운 핸들러를 만들어보도록 하자.
import { Controller, Get, Post } from '@nestjs/common';
@Controller('cats')
export class CatsController {
@Get()
findAll(): string {
return 'This action returns all cats';
}
@Post()
create(): string {
return 'This action adds a new cat';
}
}
굉장히 간단하며, Nest는 표준의 Http 메서드를 데코레이터를 통해 모두 지원한다.
만약 모든 메서드를 지원하는 엔드포인트를 만들고 싶다면 @All() 데코레이터를 사용하면 된다.
Route wildcards
패턴을 통해서 라우트하는 기능도 Nest는 지원한다. *을 사용하면 와일드카드로 해당 위치에는 어떤 조합의 경로도 라우트해준다.
아래의 예시처럼 사용하면 seungkyu/ 뒤의 경로로 어떤 문자열이 오더라도 해당 핸들러로 라우팅해준다.
@Get('abcd/*')
findAll(){
return 'This route uses a wildcard';
}
Status code
기본적인 응답 코드는 항상 200이고, POST 메서드의 응답코드는 항상 201이다.
이거를 @HttpCode()를 통해 핸들러 레벨에서 쉽게 바꿀 수 있다.
@Post()
@HttpCode(204)
create(){
return 'This action adds a new cat';
}
물론 중간에 에러가 발생하면 바뀌기도 하며, @Res() 혹은 @Response()를 사용해서 직접 넘길 때도 바뀌기도 한다.
Response headers
response의 header를 직접 명시하기 위해, @Header() 데코레이터를 사용할 수 있다.
물론 res.header()를 통해서 직접 접근도 가능은 하다.
@Post()
@Header('Cache-Control', 'no-store')
create(){
return 'This action adds a new cat';
}
Redirection
특정 주소로 리다이렉트 하고 싶다면, @Redirect() 데코레이터에 url과 statusCode를 명시해주면 된다.
만약 statusCode를 명시하지 않는다면, statusCode의 기본값은 302이다.
@Get()
@Redirect('https://nestjs.com', 301)
Route parameters
정적인 경로만으로 요청하면, 원하는 동적 데이터들을 받을 수 없다.
만약 id와 같은 값을 동적으로 받아오고 싶다면, 파라미터 토큰을 넣어서 가져올 수 있다.
Nest 인스턴스를 만들기 위해서는 저 NestFactory.create를 사용해야 한다.
NestFactory.create()는 다음과 같이 INestApplication 인터페이스를 반환한다. 이 인터페이스는 여러가지 메서드들을 제공하며, 이 main.ts에서는 그냥 단순히 Http Listener를 만들어주는 것이다.
이제 이 nest의 개발 방법에 따라 개발자가 기능을 확장해나가면 된다.
플렛폼
Nest는 플랫폼에 종속되지 않는 것에 목적을 두었다. 플랫폼에서 독립적이라면 비즈니스 로직을 다른 타입의 애플리케이션 간에 재사용 할 수 있으니 말이다. 기술적으로 Nest는 Node의 웹 프레임워크에서나 사용가능하다. 여기 2개의 바로 사용가능한 플랫폼이 존재한다. 바로 express와 fastify다.
platform-express
express는 가장 잘 알려진 경량화 node 웹 프레임워크다. 실무에서 이미 검증된 프레임워크로 커뮤니티에서 많은 리소스들을 재공한다. @nestjs/platform-express는 기본적으로 platform-express를 사용하며, 이 플랫폼을 사용하기 위해서는 별도의 조치는 필요없다.
platform-fastify
Fastify는 높은 성능과 적은 오버헤드에 초점을 둔 프레임워크이다.
어떤 프레임워크를 사용하더라도 이렇게 상속받아서 nest를 동작할 수 있다.
애플리케이션 실행
설치가 완료되었다면, 아래와 같은 명령어를 입력하여 들어오는 Http 요청을 받을 수 있다.
Nest는 node.js 서버를 더 효율적이고 확장가능하도록 돕기 위한 프레임워크이다. Nest는 최신 자바스크립트 문법과 타입스크립트를 완벽하게 지원하며, 이를 통해 객체지향프로그래밍, 함수형 프로그래밍, 반응형 프로그래밍을 사용하여 개발할 수 있다.
Nest는 내부적으로 Express 위에서 동작하지만, 선택적으로 Fastify에서도 동작이 가능하다.
Nest는 node.js 프레임워크에서 직접 라우터를 짜지 않아도, 상위 추상화 개념을 이용하여 개발 할 수 있도록 한다.
Philosophy
최근 몇 년 동안 Node.js 덕분에 Javascript는 웹의 프론트와 백에서 공용어가 되었습니다. 하지만 Angular, React, Vue와 같이 훌륭한 프론트엔드 애플리케이션이 등장했지만, 서버에서의 Node.js는 아키텍처라는 근본적인 문제를 효과적으로 해결하지는 못했습니다.
Nest는 개발자가 효과적으로 테스트하고, 확장가능하고, 느슨하게 결합하고, 애플리케이션을 쉽게 유지보수 할 수 있도록 즉시 사용가능한 애플리케이션을 제공한다.
Installation
시작을 하기 위해서는 Nest cli 혹은, starter project를 clone 하는 방법으로 기본 틀을 가져올 수 있다.
Nest cli 방법을 사용하기 위해서는 다음의 명령어를 따라가면 된다. 이것은 새로운 디렉토리를 만들며, 해당 디렉토리를 Nest 파일과 모듈로 채우게 된다.
npm i -g @nestjs/cli
nest new {project-name}
이렇게 틀을 받아오고,
npm run start
로 서버를 실행해서 http://localhost:3000/ 에 접속하면 페이지가 보일것이다.
하지만 저번에 EmbeddedDatabaseBuilder를 사용했던 것을 떠올리며, 결국 해당 타입으로 주입을 하게 되는 것이기에 그렇게 만들어서 넣어준다.
@Bean
public DataSource embeddedDataSource() {
return new EmbeddedDatabaseBuilder()
.setName("embeddedDatabase")
.setType(EmbeddedDatabaseType.H2)
.addScript("/schema.sql").build();
}
메서드의 이름은 우리가 등록했던 bean의 id로 해준다.
마지막으로 트랜잭션 어노테이션을 위해 해당 어노테이션까지 TestApplicationContext에 붙여준다.
@EnableTransactionManagement
이렇게해서 모든 bean을 옮겼다.
초기 테스트를 위해서 붙였던 @ImportResource를 지금은 제거가 가능하다.
그렇게 수정하고 테스트를 돌려보니 성공하는 것을 볼 수 있었다.
빈 스캐닝과 자동와이어링
이렇게 만든 빈들을 생성자나 setter를 통해 주입해야한다.
스프링은 @Autowired가 붙은 수정자 메서드가 있으면 타입을 보고 주입 할 수 있는 빈을 주입한다.
만약 타입으로 주입 가능한 빈이 2개 이상이면, 그 중에서 해당 프로퍼티와 동일한 이름의 빈으로 주입한다.
그렇기에 이렇게 동일한 타입이 2개라도 각각의 이름을 통해서 빈을 주입 가능한 것이다.
@Bean
public DataSource dataSource() {}
@Bean
public DataSource embeddedDataSource() {}
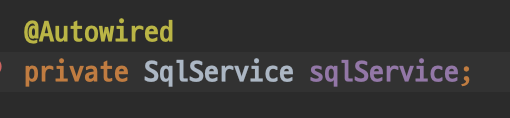
@Autowired
public UserDaoImpl(
DataSource dataSource,
SqlService sqlService) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
this.sqlService = sqlService;
}
이렇게 DataSource로 받지만, 실제 사용하는건 JdbcTemplate과 같은 경우 JdbcTemplate을 주입받을 수는 없으니 반드시 setter나 생성자를 통해 주입 받아야 한다.
@Component를 통해서도 빈 등록이 가능하다.
이 @Component는 클래스에 사용하는 어노테이션이고, 이 어노테이션이 부여된 클래스는 자동으로 빈으로 등록된다.
현재 작성한 UserDaoImpl을 보면
@Component
public class UserDaoImpl implements UserDao {
//
}
이렇게 해당 클래스에 @Component를 붙이는 것 만으로도
@Bean
public UserDao userDao() {
return new UserDaoImpl(dataSource(), sqlService());
}
이거를 대체할 수 있다는 것이다.
대신에 @ComponentScan을 통해 @Component들을 검색할 범위를 지정해야 한다.
@Configuration
@EnableTransactionManagement
@ComponentScan(basePackages = "seungkyu")
public class TestApplicationContext { }
이렇게 범위를 지정해서 그 패키지들의 하위 클래스들을 검색하도록 해야한다.
@Component에서 클래스는 해당 클래스로 등록하고, 빈의 아이디는 특별하게 지정하지 않으면 클래스의 이름을 첫글자 소문자로 바꿔서 사용한다.
현재 UserDaoImpl이기에 빈의 아이디는 userDaoImpl로 지정이 되겠지만, UserDao의 구현체이기에 해당 UserDao의 타입으로도 주입이 되게 된다.
@Target({ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Component
public @interface SeungkyuComponent {
}
이런 식으로 @Component 어노테이션을 가지고 있는 어노테이션은 빈으로 등록이 된다.
그런 빈 중에서도 @Service, @Repository와 같은 특별한 역할을 하는 빈들이 있기에 맞게 달아주도록 하자.
여기는 현재 데이터베이스에 접근하는 코드이니 @Repository를 붙여주도록 하겠다.
빈을 등록하다보면 다음과 같은 상황이 생길 수 있다.
타입으로 주입을 시도하려고 했지만, 같은 타입이 2개 있고 이름으로도 주입할 수 없는 상황이다.
기존에는 UserServiceImpl을 UserService로 id를 지정해서 빈을 등록했지만, 지금은 클래스의 이름으로 등록이 되었기에 저 중 어떤 id도 userService와 맞지 않아 어떤 빈을 주입할지 에러가 생긴 것이다.
이 문제를 해결해주기 위해서는 다시 UserServiceImpl을 UserService로 등록해주면 된다.
@Component("userService")
@RequiredArgsConstructor
public class UserServiceImpl implements UserService{}
이 방법으로 빈을 등록해주도록 하자.
그러면 나머지 이 testUserServiceImpl은 어떻게 사용하게 될까?
컨텍스트 분리와 @Import
이렇게 DI를 사용해왔던 이유는 언젠가 사용할 테스트 때문이다.
그리고 지금 이 testUserServiceImpl도 테스트 때에만 사용하기에 어떻게 처리를 할지 고민하는 것이다.
다른 애플리케이션 빈에서는 분리하는 것이 더 좋아보인다.
일단 테스트에서 사용할 빈들을 따로 빼두는 Configuration을 만들어보자.
@Configuration
public class TestAppContext {
@Autowired UserDao userDao;
@Bean
public UserService testUserService(){
return new TestUserServiceImpl(userDao, mailSender());
}
@Bean
public MailSender mailSender() {
return new MailSenderTest();
}
}
이제 테스트 환경에서는 이거를 주입하면 될 거 같다.
그렇다고 이거를 ComponentScan의 범위로 넣을 수는 없을 것이기에, 해당 테스트 환경에서만 주입해주도록 해야한다.
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = {TestApplicationContext.class, TestAppContext.class})
class UserDaoTest {}
마지막으로 데이터베이스 연결과 같은 부분도 분리하도록 하겠다.
결국 Configuration에도 같은 관심사끼리 모아두는 것이 유지보수에는 유리할 것이다.
@Configuration
public class SqlServiceContext {
@Bean
public SqlRegistry sqlRegistry() {
return new ConcurrentHashMapSqlRegistry();
}
@Bean
public SqlReader sqlReader() {
return new YmlSqlReader("/sqlmap.yml");
}
@Bean
public SqlService sqlService() {
return new YmlSqlService(sqlReader(), sqlRegistry());
}
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.setName("embeddedDatabase")
.setType(EmbeddedDatabaseType.H2)
.addScript("/schema.sql")
.build();
}
}
이렇게 일단 지금 가지고 있는건 SqlServiceContext, TestAppContext, TestApplicationContext 이렇게 3개이다.
일단 혼동되지 않게 TestApplicationContext를 AppContext로 바꿔주자.
이거를 모두 배열로 @ContextConfiguration에 넣어줘야 할까?
하지만 여기서 의존관계를 살펴보면 SqlServiceContext를 AppContext가 필요로하고, 솔직히 테스트 클래스나 TestAppContext는 관심이 없다.
그렇기에 SqlServiceContext를 AppContext에만 직접 넣어주도록 만들어주는 것이 좋을 것 같다.
@Import(SqlServiceContext.class)
public class AppContext {}
이 방법으로 직접 넣어주고 다른 부분은 수정하지 않도록 만들자.
프로파일
현재 방법은 다음과 같은 문제가 있다.
현재 운영, 테스트가 공통으로 사용하는 AppContext와 TestAppContext 이렇게 2개가 있고 여기 모두에서 UserService 타입의 빈이 정의되어있다.
하나는 MailSenderImpl 타입이고 다른 하나는 MailSenderTest이다.
그럼 MailSender를 주입 받을 때, 어떤 타입을 주입받게 될까.
지금도 이렇게 충돌이 일어나고 있고, 우리는 테스트 환경에서는 testUserService를 데리고 오고 싶은 것이다.
이렇게 테스트 환경과 운영환경에서 각각 다른 빈을 가져와야 하는 경우가 많다.
스프링은 이렇게 환경에 따라서 빈 설정정보가 달라져야 하는 경우에 간단하게 해당 설정들을 만들 수 있도록 방법을 제공한다.
프로파일은 클래스 단위로 지정한다.
@Profile 어노테이션을 사용해서 프로파일의 이름을 넣어주면 된다.
@Configuration
@Profile("test")
public class TestAppContext {
}
이제 이렇게 하고 실행을 해보면, 당연히 실패한다.
MailSender를 가져오지 못해 실패하는데, 따로 저 profile을 활성화해주지 않아 에러가 발생하는 것이다.
@ExtendWith(SpringExtension.class)
@ContextConfiguration(classes = {AppContext.class, TestAppContext.class, ProductionAppContext.class})
@ActiveProfiles("test")
class UserDaoTest {}
이렇게 ActiveProfiles로 test를 활성화 해줘야, test의 profile들을 불러오게 된다.
이렇게 설정을 하고 다시 테스트를 돌려보니, 다음과 같이 성공하는 것을 볼 수 있다.
프로퍼티 소스
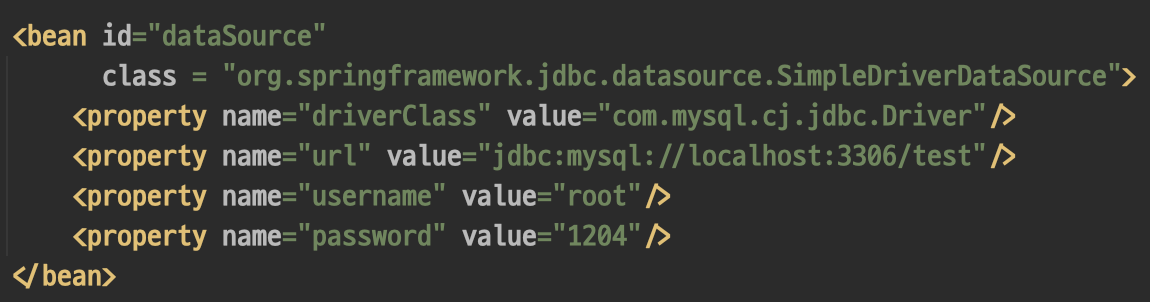
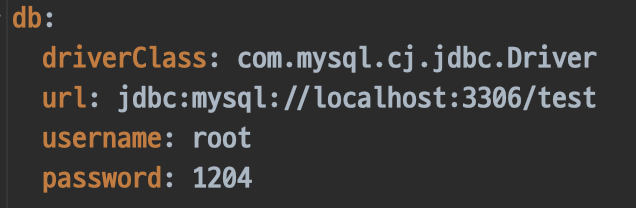
현재 데이터베이스의 정보가 이렇게 코드로 들어가있다.
이런 정보가 깃에 올라가면 안되기도 하고, 배포서버와 개발서버에서 다른 데이터베이스를 연결하기에 이런 정보는 코드로 작성해서는 안된다.
프로퍼티 파일로 빼도록 하자.
database.yml라는 파일을 만들고 데이터베이스의 정보는 그곳에다가 저장하도록 하겠다.
package seungkyu;
import org.springframework.dao.EmptyResultDataAccessException;
import org.springframework.data.crossstore.ChangeSetPersister;
import org.springframework.jdbc.core.JdbcTemplate;
import javax.sql.DataSource;
import java.util.Map;
public class EmbeddedDbSqlRegistry implements UpdatableSqlRegistry {
private final JdbcTemplate jdbcTemplate;
public EmbeddedDbSqlRegistry(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
@Override
public void registerSql(String key, String sql) {
jdbcTemplate.update("INSERT INTO sqlmap (key_, sql_) values (?, ?)", key, sql);
}
@Override
public String findSql(String key) {
try
{
return jdbcTemplate.queryForObject("SELECT sql_ FROM sqlmap WHERE key_ = ?", String.class, key);
}
catch(EmptyResultDataAccessException e)
{
throw new RuntimeException();
}
}
@Override
public void updateSql(String key, String sql) {
int changed = jdbcTemplate.update("UPDATE sqlmap SET sql_ = ? WHERE key_ = ?", sql, key);
}
@Override
public void updateSql(Map<String, String> sqlmap) {
for(Map.Entry<String, String> entry : sqlmap.entrySet()) {
this.updateSql(entry.getKey(), entry.getValue());
}
}
}
이제 이 EmbeddedDbSqlRegistry를 테스트 해봐야 한다.
근데 재미있게도 ConcurrentHashMapSqlRegistry와 구현한 인터페이스가 같다.
그리고 우리는 그 인터페이스의 내용만 테스트하면 끝이다.
그렇기에 해당 테스트 코드를 공유해보자.
이런식으로 추상 클래스를 만들고
public abstract class AbstractUpdatableSqlRegistryTest {
UpdatableSqlRegistry sqlRegistry;
abstract protected UpdatableSqlRegistry injectSqlRegistry();
@BeforeEach
public void setUp() {
sqlRegistry = injectSqlRegistry();
sqlRegistry.registerSql("KEY1", "SQL1");
sqlRegistry.registerSql("KEY2", "SQL2");
sqlRegistry.registerSql("KEY3", "SQL3");
}
//.....
}
기존의 ConcurrentHashMapSqlRegistryTest도 이렇게 간단하게 변경했다.
public class ConcurrentHashMapSqlRegistryTest extends AbstractUpdatableSqlRegistryTest{
@Override
protected UpdatableSqlRegistry injectSqlRegistry() {
return new ConcurrentHashMapSqlRegistry();
}
}
이렇게만 작성하고 테스트를 해봐도
기존에 작성한 4개의 테스트를 수행하는 것을 볼 수 있다.
이거를 그대로 상속받아 EmbeddedDbSqlRegistryTest를 만들어보자.
public class EmbeddedDbSqlRegistryTest extends AbstractUpdatableSqlRegistryTest{
EmbeddedDatabase db;
@Override
protected UpdatableSqlRegistry injectSqlRegistry() {
db = new EmbeddedDatabaseBuilder()
.setType(EmbeddedDatabaseType.H2)
.addScript("/schema.sql")
.build();
return new EmbeddedDbSqlRegistry(db);
}
@AfterEach
public void tearDown() {
db.shutdown();
}
}
이렇게 작성하고 테스트를 실행해보니, 다행하게 통과하는 것을 볼 수 있었다.
이제 저 EmbeddedDbSqlRegistry에 DataSource를 주입해줘야 한다.
아무생각없이 DataSource를 찾아 넣으면 MySql로 들어가기에 내장 데이터베이스를 잘 찾아서 넣어줘야 한다.