인프런 김영한 님의 강의를 참고했습니다.
스프링 핵심 원리 - 기본편 - 인프런 | 강의
스프링 입문자가 예제를 만들어가면서 스프링의 핵심 원리를 이해하고, 스프링 기본기를 확실히 다질 수 있습니다., - 강의 소개 | 인프런...
www.inflearn.com
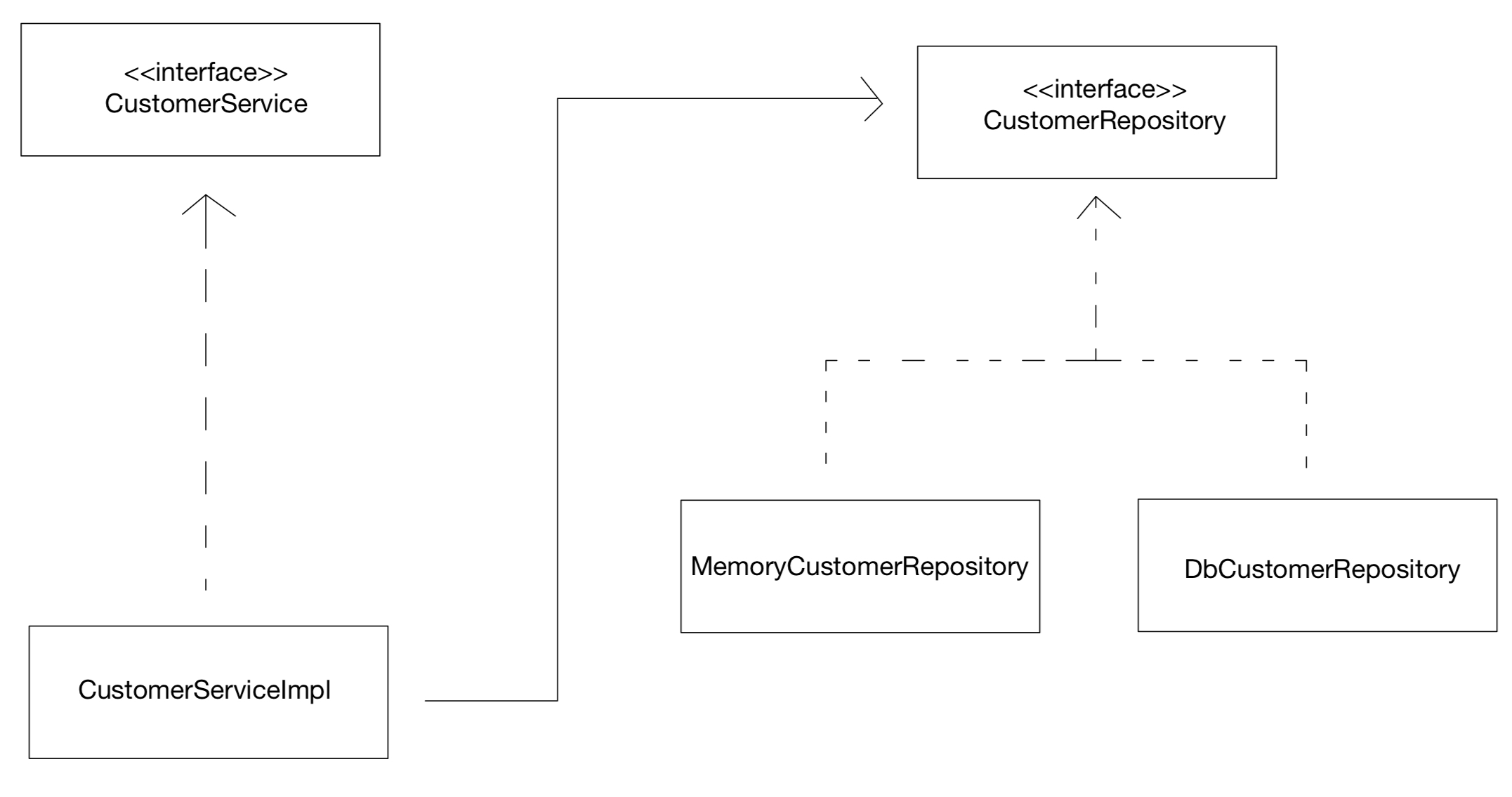
다양한 의존관계 주입 방법
의존관계 주입은 4가지 방법이 있다.
- 생성자 주입
- 수정자 주입
- 필드 주입
- 일반 메서드 주입
- 생성자 주입
말 그대로 생성자를 통해서 의존 관계를 주입받는다.
이제까지 우리가 사용했던 방법이며, 생성자가 호출되는 시점에서 딱 1번만 호출된다.
불변, 필수 의존관계에 사용이 된다.
생성자에 @Autowired를 달아서 사용하며, 생성자가 하나만 있으면 생략이 가능하다.
package hello.core.order;
import hello.core.Discount.DiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.CustomerRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class OrderServiceImpl implements OrderService{
private final CustomerRepository customerRepository;
//private final DiscountPolicy discountPolicy = new FixDiscountPolicy();
private final DiscountPolicy discountPolicy;
@Autowired
public OrderServiceImpl(CustomerRepository customerRepository, DiscountPolicy discountPolicy) {
this.customerRepository = customerRepository;
this.discountPolicy = discountPolicy;
}
}
- 수정자 주입(setter 주입)
setter를 만들고 그 메서드를 통해서 의존관계를 주입하는 방법이다.
선택, 변경 가능성이 있는 의존관계에 사용한다.
@Component
public class OrderServiceImpl implements OrderService{
private CustomerRepository customerRepository;
private DiscountPolicy discountPolicy;
@Autowired
public void setCustomerRepository(CustomerRepository customerRepository){
this.customerRepository = customerRepository;
}
@Autowired
public void setDiscountPolicy(DiscountPolicy discountPolicy){
this.discountPolicy = discountPolicy;
}
}@Autowired는 주입할 대상이 없으면 오류가 발생한다.
주입할 대상이 없어도 동작하게 하려면 @Autowired(required = false)로 지정해야 한다.
- 필드주입
이름 그대로 필드에 주입하는 방법이다.
코드는 간단하지만, 사용하지 말자.
외부에서 변경이 불가능해 테스트가 힘들고, DI 프레임워크가 없으면 아무것도 할 수 없다.
@Component
public class OrderServiceImpl implements OrderService{
@Autowired
private CustomerRepository customerRepository;
@Autowired
private DiscountPolicy discountPolicy;
}
- 일반 메서드 주입
당연히 일반 메서드를 통해서도 주입 받을 수 있다.
하지만 일반적으로 잘 사용하지는 않는다.
@Component
public calss OrderServiceImpl implements OrderService{
private CustomerRepository customerRepository;
private DiscountPolicy discountPolicy;
@Autowired
public void init(CustomerRepository customerRepository, DiscountPolicy discountPolicy){
this.customerRepository = customerRepository;
this.discountPolicy = discountPolicy;
}
}
가끔은 주입할 스프링 빈이 없어도 동작을 해야한다.
그럴 때는 위에서 말한 방법처럼 @Autowired(required = false)를 사용할 수 있다.
이외에도 방법들이 더 있는데
package hello.core.autowired;
import hello.core.customer.Customer;
import jakarta.annotation.Nullable;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import java.util.Optional;
public class AutowiredTest {
@Test
void AutowiredOption(){
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(TestBean.class);
}
static class TestBean{
@Autowired(required = false)
public void setNoBean1(Customer noBean1){
System.out.println("noBean1 = " + noBean1);
}
@Autowired
public void setNoBean2(@Nullable Customer noBean2){
System.out.println("noBean2 = " + noBean2);
}
@Autowired
public void setNoBean3(Optional<Customer> noBean3){
System.out.println("noBean3 = " + noBean3);
}
}
}@Autowired(required = false): 자동 주입할 대상이 없으면 메서드가 호출이 되지 않는다.
@Nullable: 자동 주입할 대상이 없으면 null이 입력된다.
Optional<>: 자동 주입할 대상이 없으면 Optional.empty가 입력된다.
이렇게 주입에는 많은 방법들이 있지만, 생성자 주입이 가장 좋다고 한다.
대부분의 의존관계들은 변경할 필요가 없으며, final로 사용할 수 있고, setter로 의도하지 않은 수정이 일어나지 않기 때문에 가장 좋다.
Lombok
우리는 의존관계를 생성자를 통해 주입하기로 하였다.
그러면 이 방법을 더 간단하게 할 수 없을까?
그 방법이 Lombok이다.
기존에 사용하던 OrderServiceImpl이다.
package hello.core.order;
import hello.core.Discount.DiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.CustomerRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class OrderServiceImpl implements OrderService{
private final CustomerRepository customerRepository;
private final DiscountPolicy discountPolicy;
@Autowired
public OrderServiceImpl(CustomerRepository customerRepository, DiscountPolicy discountPolicy) {
this.customerRepository = customerRepository;
this.discountPolicy = discountPolicy;
}
}생성자가 하나이기 때문에 @Autowired를 생략 할 수 있다.
그리고 Lombok을 사용하면 final이 붙은 필드를 모아서 생성자를 자동으로 만들어준다.
package hello.core.order;
import hello.core.Discount.DiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.CustomerRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
@RequiredArgsConstructor
public class OrderServiceImpl implements OrderService{
private final CustomerRepository customerRepository;
private final DiscountPolicy discountPolicy;
}이렇게만 해주어도 자동으로 생성자를 만들고 의존관계를 주입해준다.
Lombok 적용하는 방법은 소개하지 않도록 하겠다.
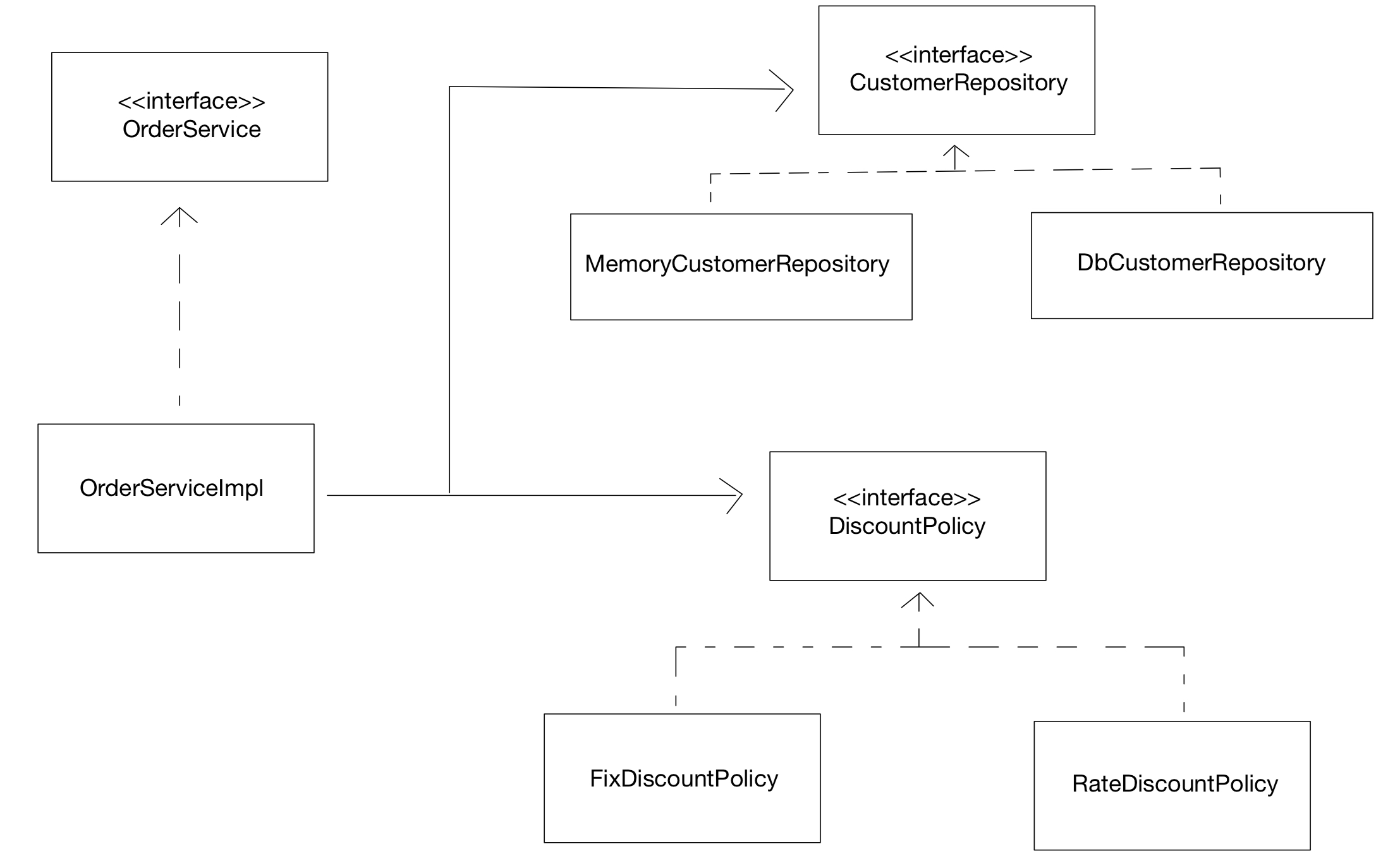
조회 빈이 2개 이상
@Autowired는 타입에 맞는 의존관계를 넣어준다.
만약 같은 타입이 2가지 이상이라면 어떻게 될까?
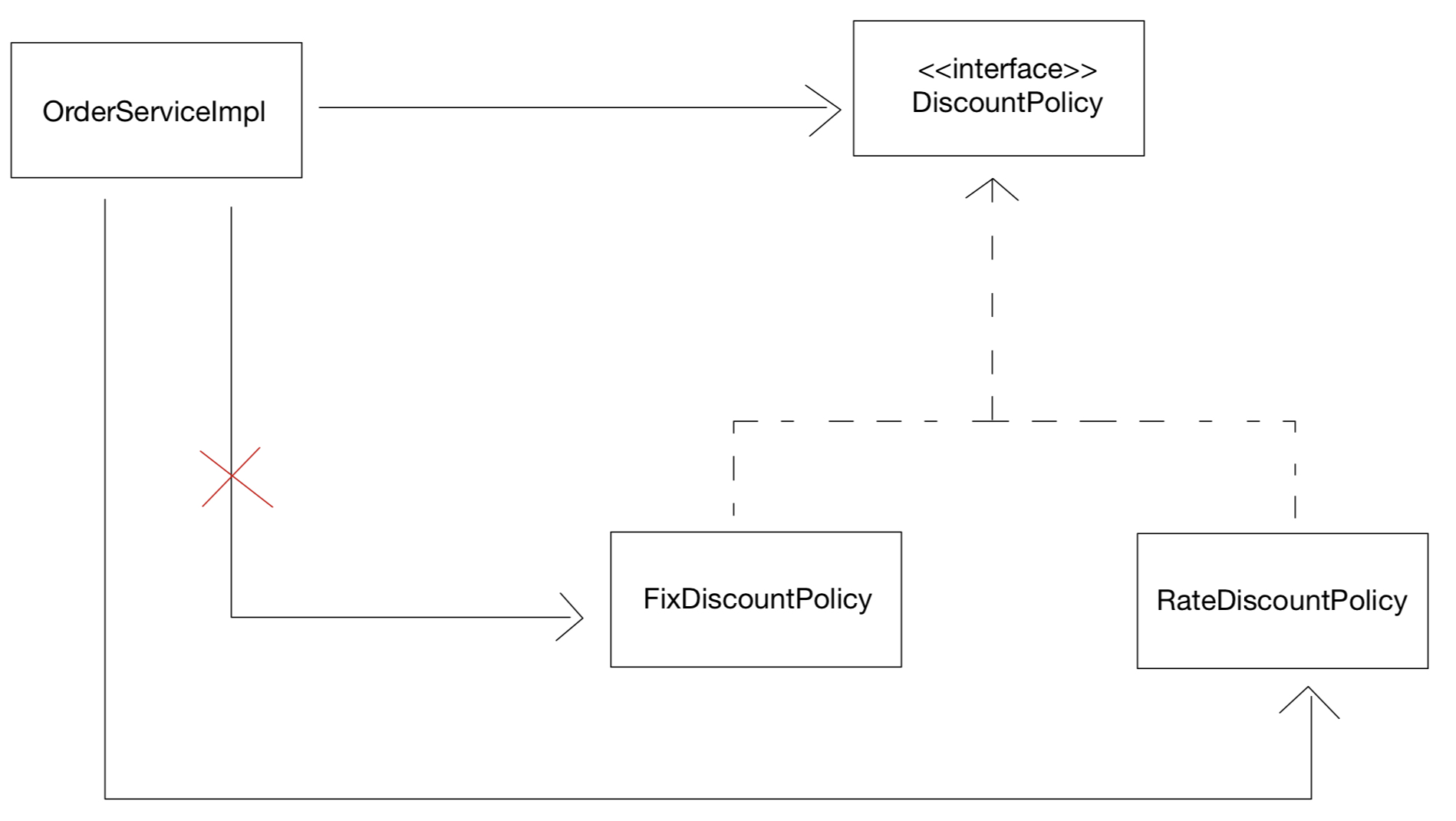
지금 DiscountPolicy에서 FixDiscountPolicy, RateDiscountPolicy가 있는 것 처럼 말이다.
일단 둘 다 @Component annotation을 달아주자.
그러고 테스트에 작성한 basicScan을 실행해보면

이런 오류가 발생하게 된다.
해결방법으로는
@Autowired 필드 명 매칭
@Qualifier
@Primary
가 있다.
- Autowired 필드 명 매칭
package hello.core.order;
import hello.core.Discount.DiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.CustomerRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class OrderServiceImpl implements OrderService{
private final CustomerRepository customerRepository;
private final DiscountPolicy discountPolicy;
public OrderServiceImpl(CustomerRepository customerRepository, DiscountPolicy discountPolicy) {
this.customerRepository = customerRepository;
this.discountPolicy = discountPolicy;
}
}기존에 이렇게 작성된 코드에서
package hello.core.order;
import hello.core.Discount.DiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.CustomerRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class OrderServiceImpl implements OrderService{
private final CustomerRepository customerRepository;
private final DiscountPolicy rateDiscountPolicy;
public OrderServiceImpl(CustomerRepository customerRepository, DiscountPolicy discountPolicy) {
this.customerRepository = customerRepository;
this.rateDiscountPolicy = discountPolicy;
}
}로 필드 명을 rateDiscountPolicy(빈 이름)으로 변경한 것이다.
이러면 우리가 원하는 rateDiscountPolicy가 주입이 된다.
- Qualifier
@Qualifier이라는 추가 구분자를 붙여주는 방법이다.
빈 이름을 변경하는 것은 아니고, 단순히 비교에만 사용한다.
이렇게 빈 등록할 때 @Qualifier를 붙여준다.
@Component
@Qualifier("rateDiscountPolicy")
public class RateDiscountPolicy implements DiscountPolicy{}@Component
@Qualifier("fixDiscountPolicy")
public class FixDiscountPolicy implements DiscountPolicy{}
이렇게 붙여주고 생성자에서
package hello.core.order;
import hello.core.Discount.DiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.CustomerRepository;
import lombok.RequiredArgsConstructor;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;
@Component
public class OrderServiceImpl implements OrderService{
private final CustomerRepository customerRepository;
private final DiscountPolicy discountPolicy;
@Autowired
public OrderServiceImpl(CustomerRepository customerRepository, @Qualifier("rateDiscountPolicy") DiscountPolicy discountPolicy) {
this.customerRepository = customerRepository;
this.discountPolicy = discountPolicy;
}
}@Qualifier를 추가해준다.
- @Primary
@Primary로 우선 순위를 정하는 방법이다.
@Autowired시에 여러개의 빈이 충돌하면 @Primary가 우선권을 가진다.
주입할 빈에 가서
@Component
@Primary
public class RateDiscountPolicy implements DiscountPolicy{}@Primary를 추가해준다.
우선순위로는 @Qualifier가 @Primary보다 더 높다.
Annotation 직접 만들기
가끔씩 annotation을 직접 만들어서 사용하기도 한다고 한다.
package hello.core.annotation;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Indexed;
import java.lang.annotation.*;
@Target({ElementType.FIELD, ElementType.METHOD, ElementType.PARAMETER, ElementType.TYPE, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Inherited
@Documented
@Qualifier("myDiscountPolicy")
public @interface MyDiscountPolicy {
}이렇게 @Component들의 요소를 끌어오고 우리가 사용할 @Qualifier도 달아준다.
@Component
@rateDiscountPolicy
public class RateDiscountPolicy implements DiscountPolicy{}그러고 이렇게 달아주면 우리가 원하는 annotation을 달아줄 수 있다.
생성자에도 이렇게 annotation을 추가해주면 된다.
package hello.core.order;
import hello.core.Discount.DiscountPolicy;
import hello.core.annotation.MyDiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.CustomerRepository;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class OrderServiceImpl implements OrderService{
private final CustomerRepository customerRepository;
private final DiscountPolicy discountPolicy;
@Autowired
public OrderServiceImpl(CustomerRepository customerRepository, @MyDiscountPolicy DiscountPolicy discountPolicy) {
this.customerRepository = customerRepository;
this.discountPolicy = discountPolicy;
}
}annotation에는 상속이라는 개념이 없지만, 여러 annotation을 모아서 사용하는 기능을 spring에서 제공해준다.
하지만 spring에서 제공하는 기능이라고 해도 너무 목적없이 막 사용하지는 말자.
다양한 빈들이 필요할 때 List, Map
다양한 빈들 중 필요한 것을 찾아서 사용할 때가 있다.
package hello.core.autowired;
import hello.core.AutoAppConfig;
import hello.core.Discount.DiscountPolicy;
import hello.core.customer.Customer;
import hello.core.customer.Grade;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import java.util.List;
import java.util.Map;
public class AllBeanTest {
@Test
void findAllBean(){
ApplicationContext applicationContext = new AnnotationConfigApplicationContext(AutoAppConfig.class, DiscountService.class);
DiscountService discountService = applicationContext.getBean(DiscountService.class);
Customer customer = new Customer(1L, "A", Grade.VIP);
int discountPrice = discountService.discount(customer, 10000, "rateDiscountPolicy");
Assertions.assertEquals(500, discountPrice);
}
static class DiscountService{
private final Map<String, DiscountPolicy> policyMap;
private final List<DiscountPolicy> policyList;
public DiscountService(Map<String, DiscountPolicy> policyMap, List<DiscountPolicy> policyList) {
this.policyMap = policyMap;
this.policyList = policyList;
System.out.println("policyMap = " + policyMap);
System.out.println("policies = "+ policyList);
}
public int discount(Customer customer, int price, String discountCode){
DiscountPolicy discountPolicy = policyMap.get(discountCode);
System.out.println("discountCode = " + discountCode);
System.out.println("discountPolicy = " + discountPolicy);
return discountPolicy.discount(customer, price);
}
}
}이 코드를 보면 discount에 관련된 빈들을 Map에 저장을 해서 검색을 하며 사용하고 있다.