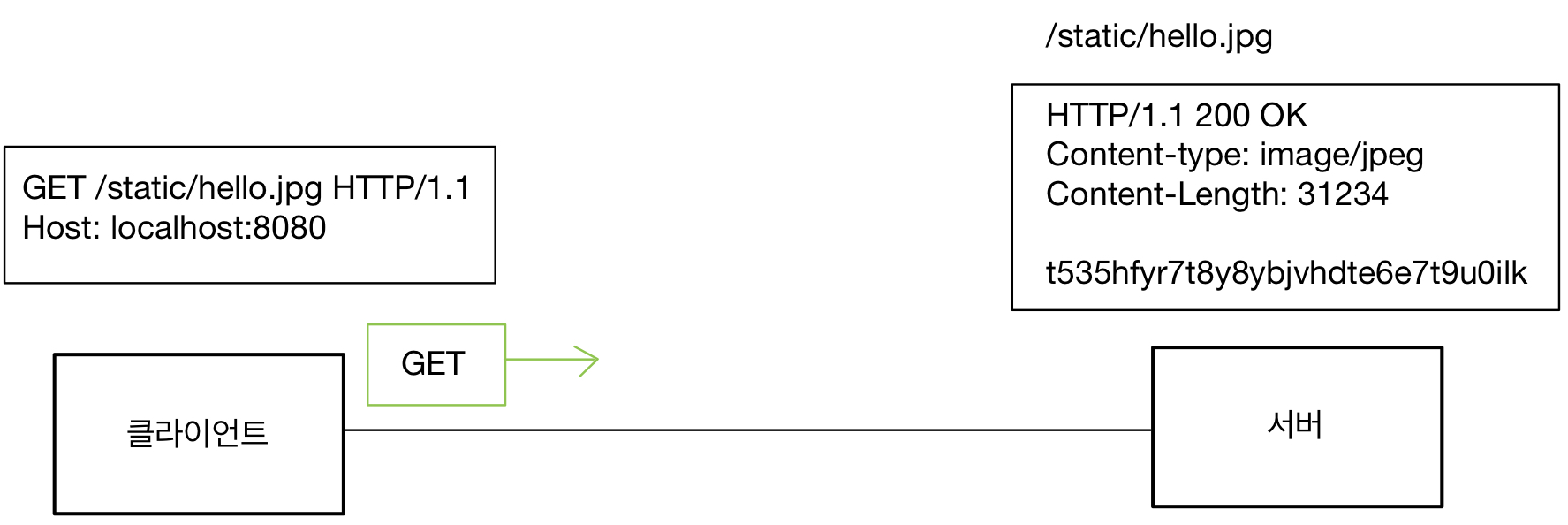
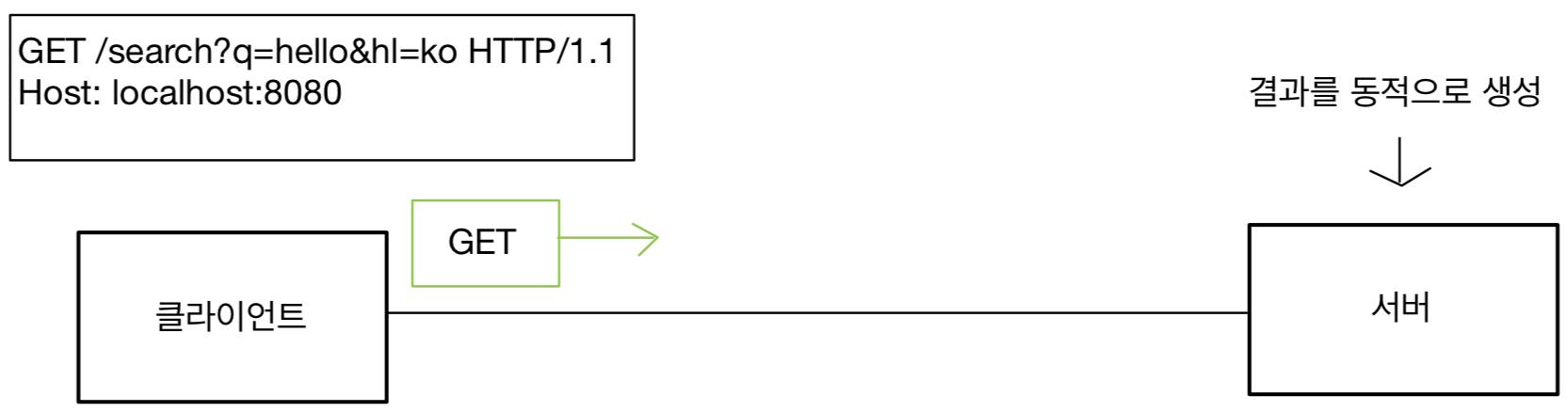
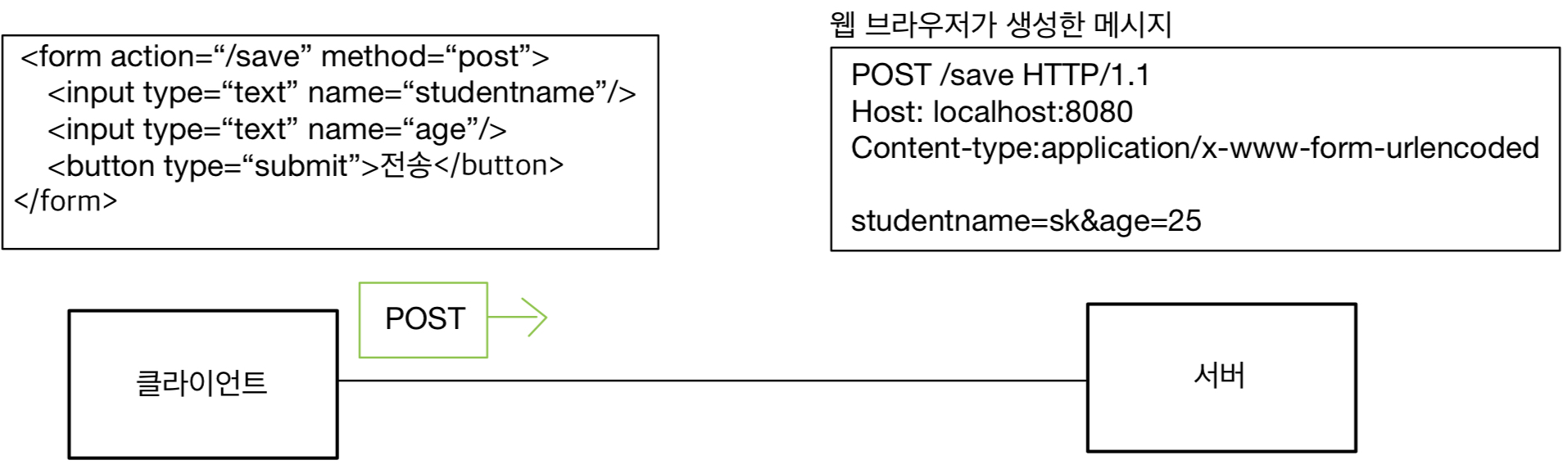
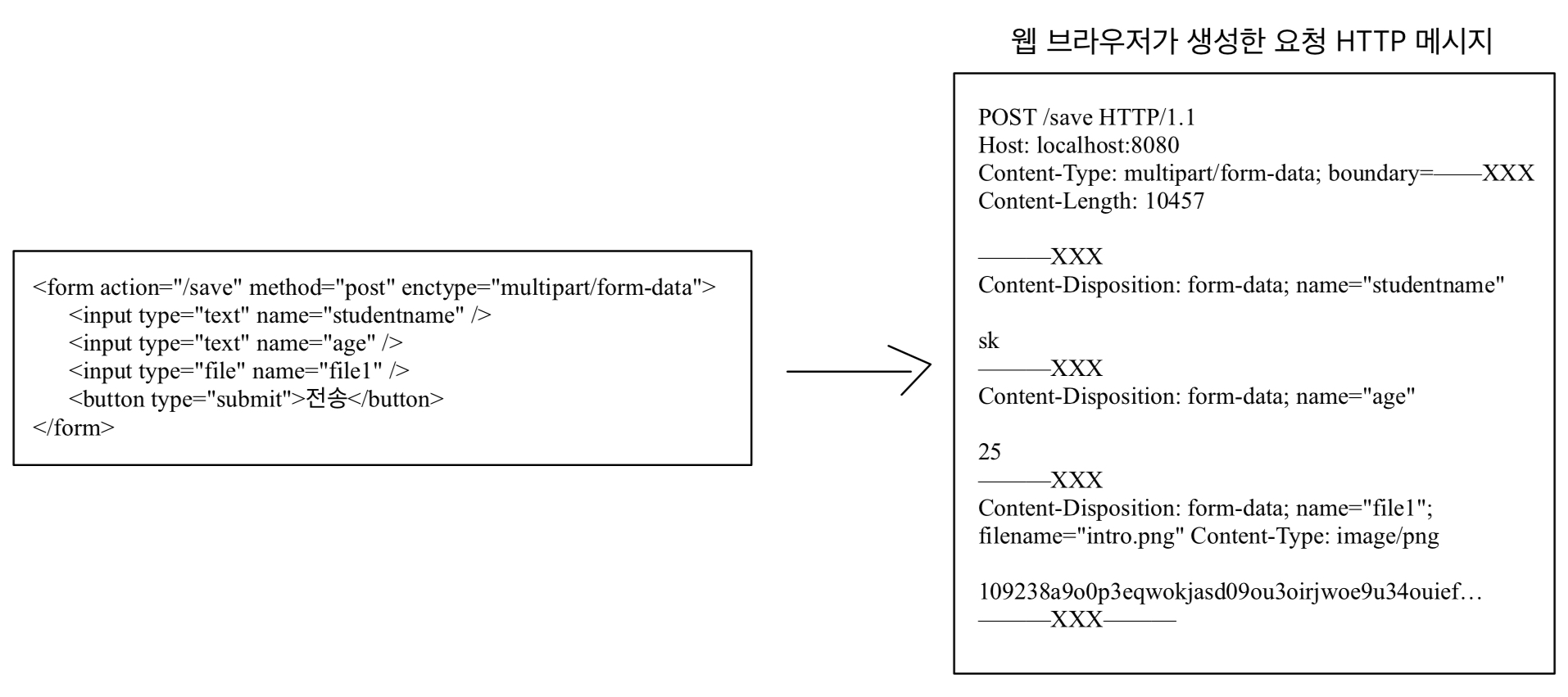
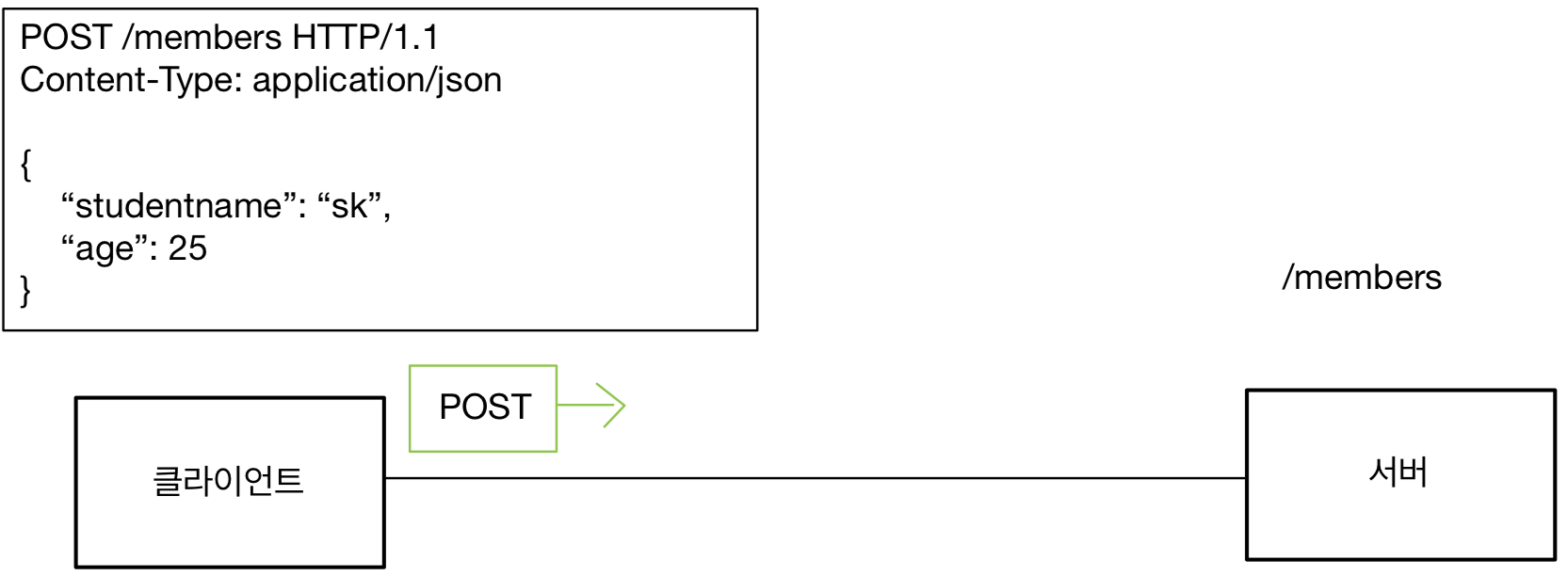
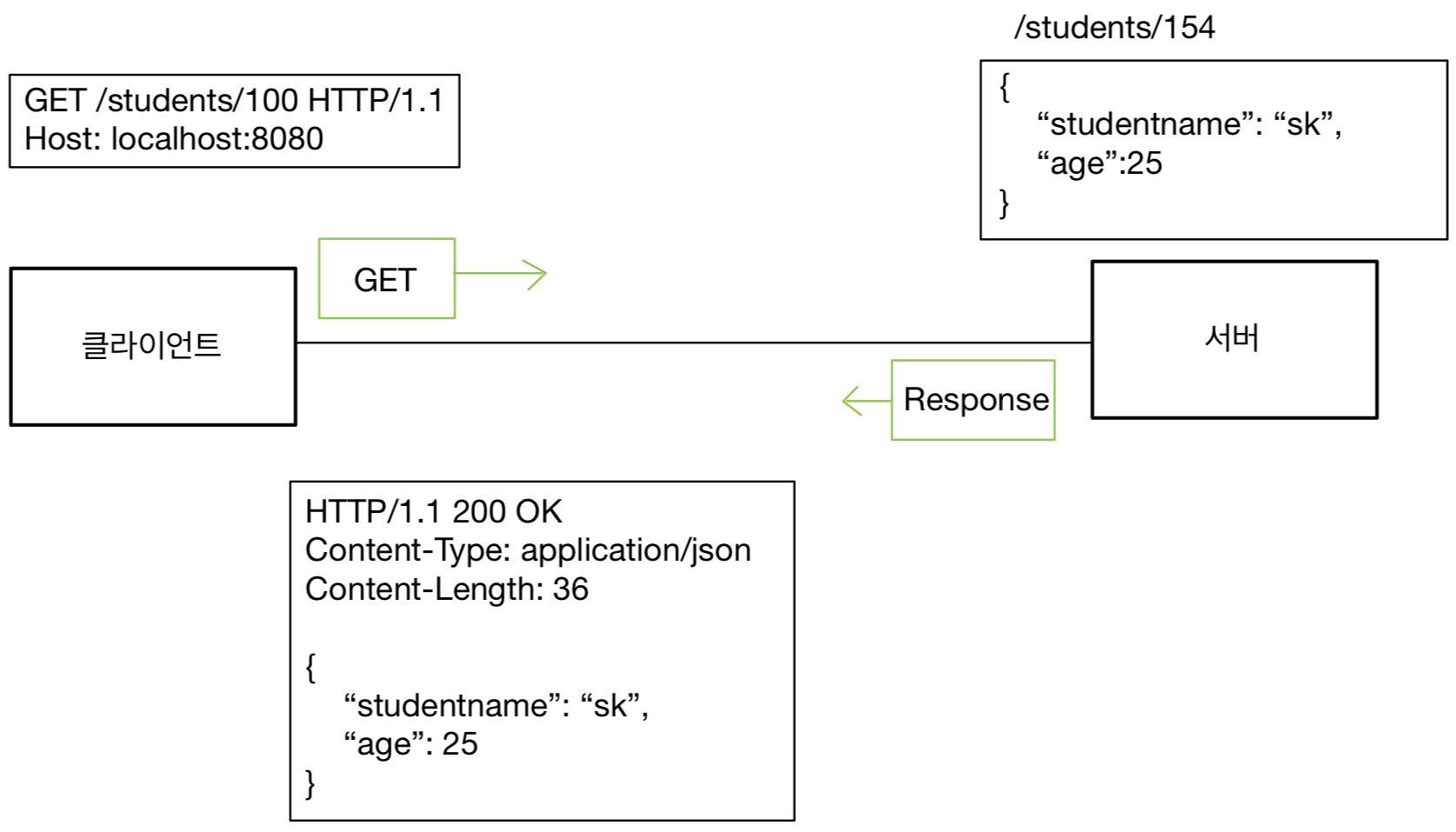
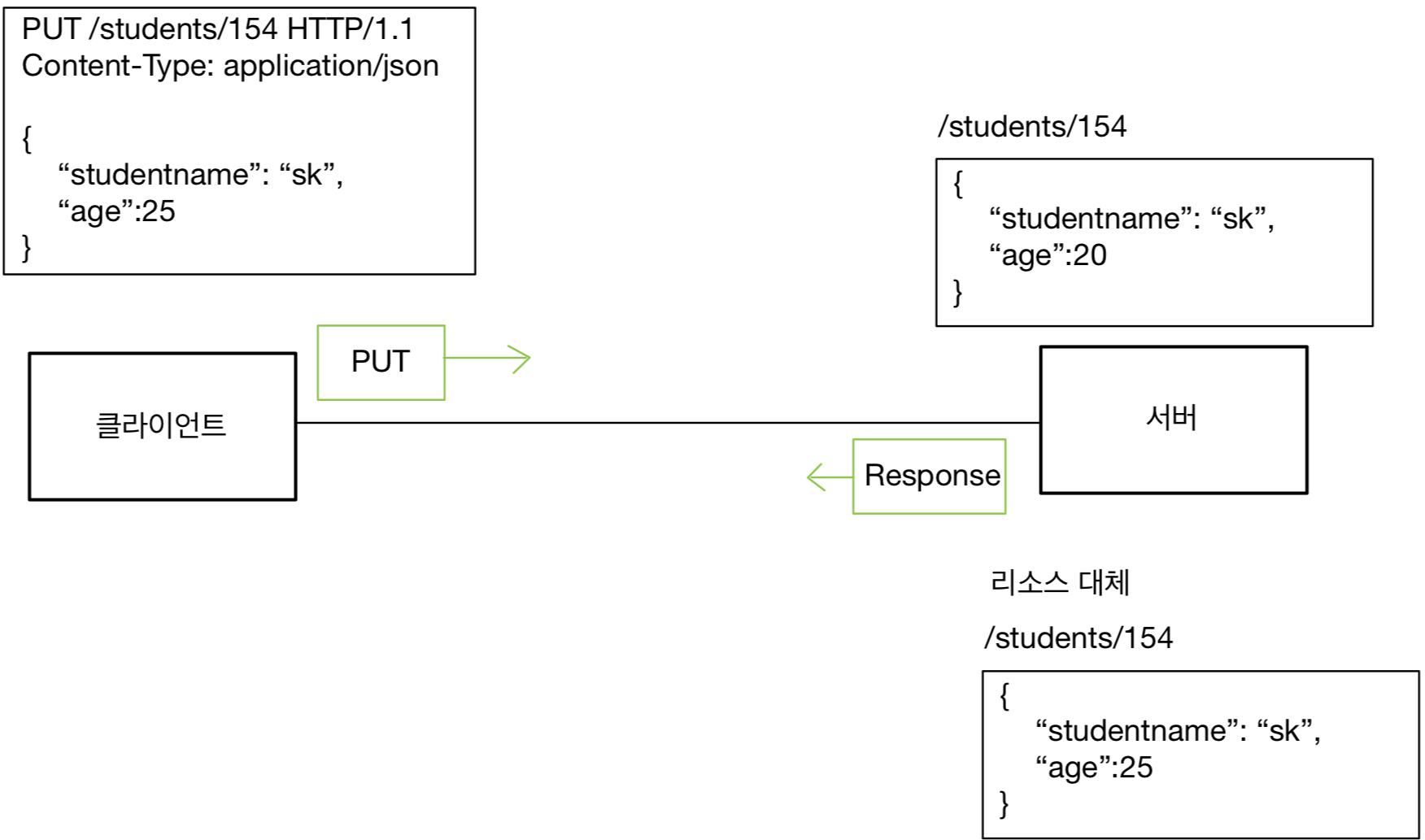
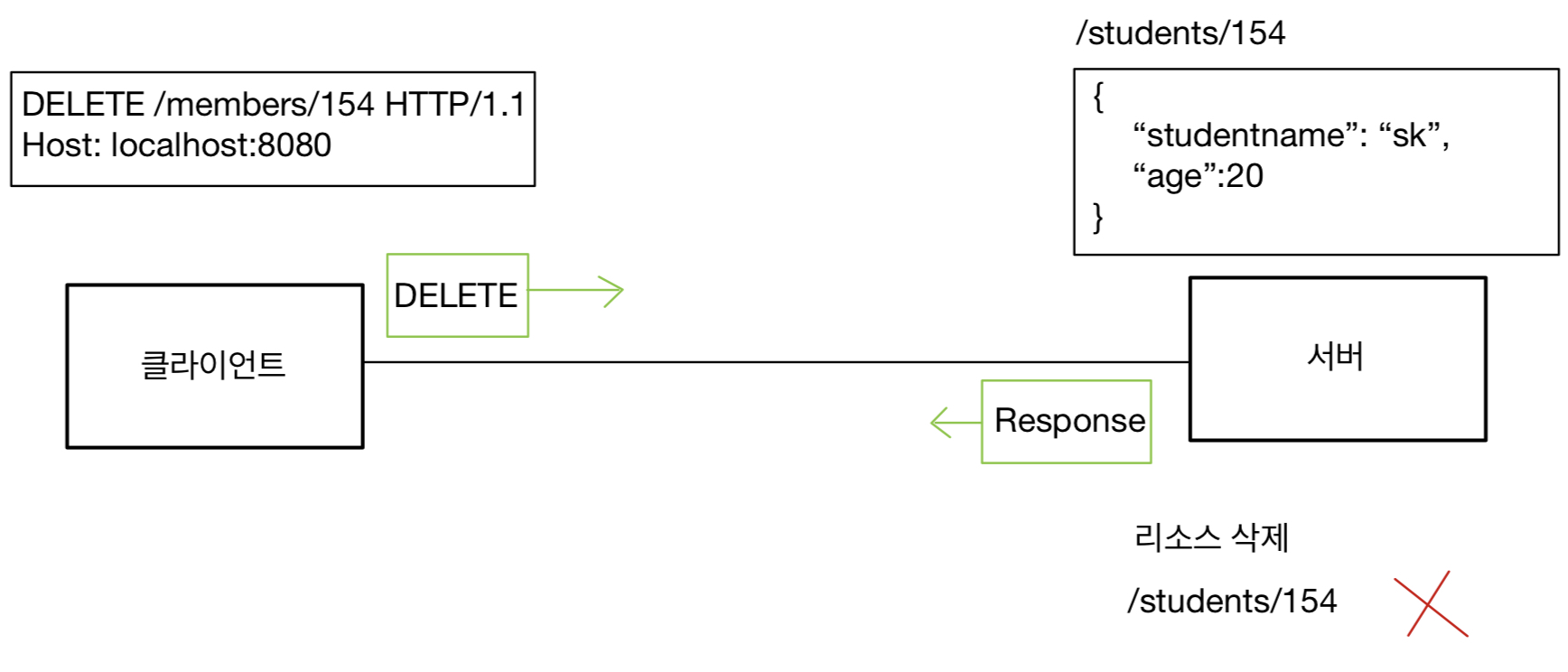
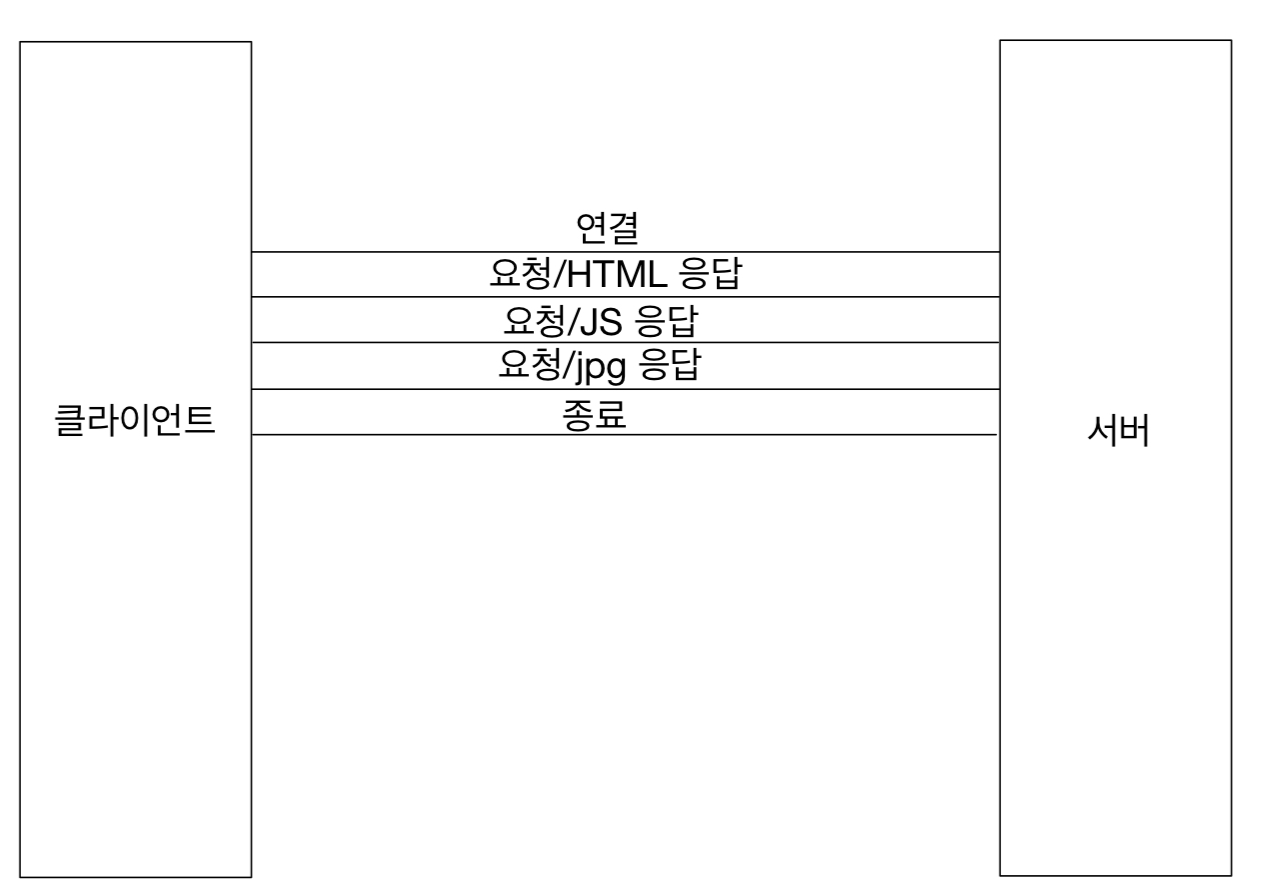
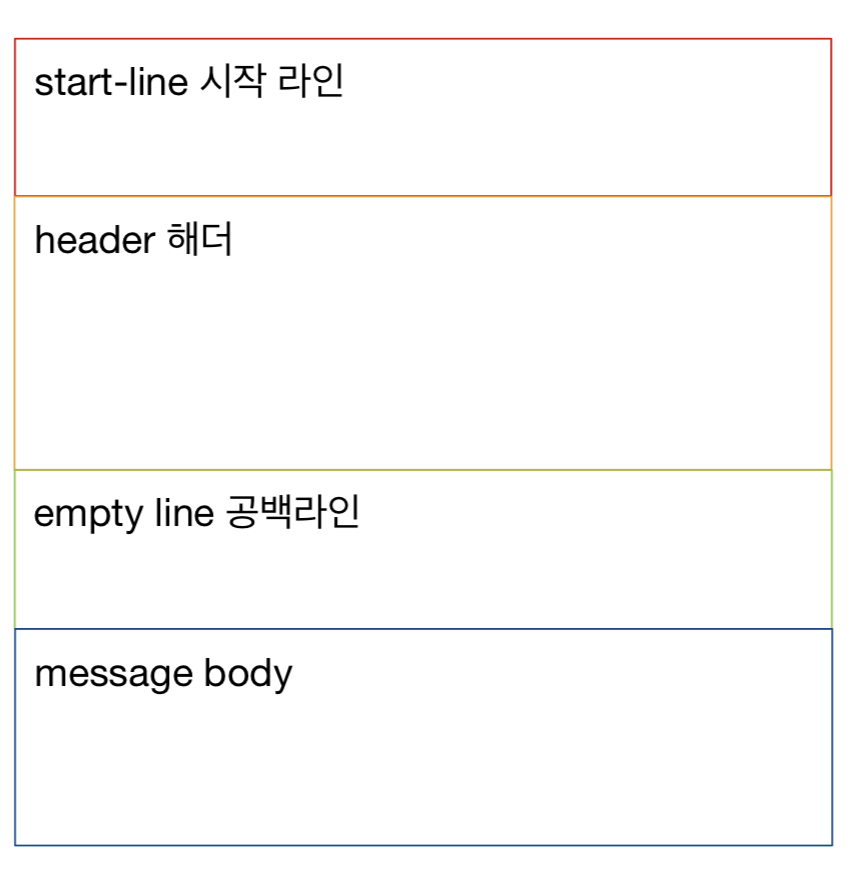
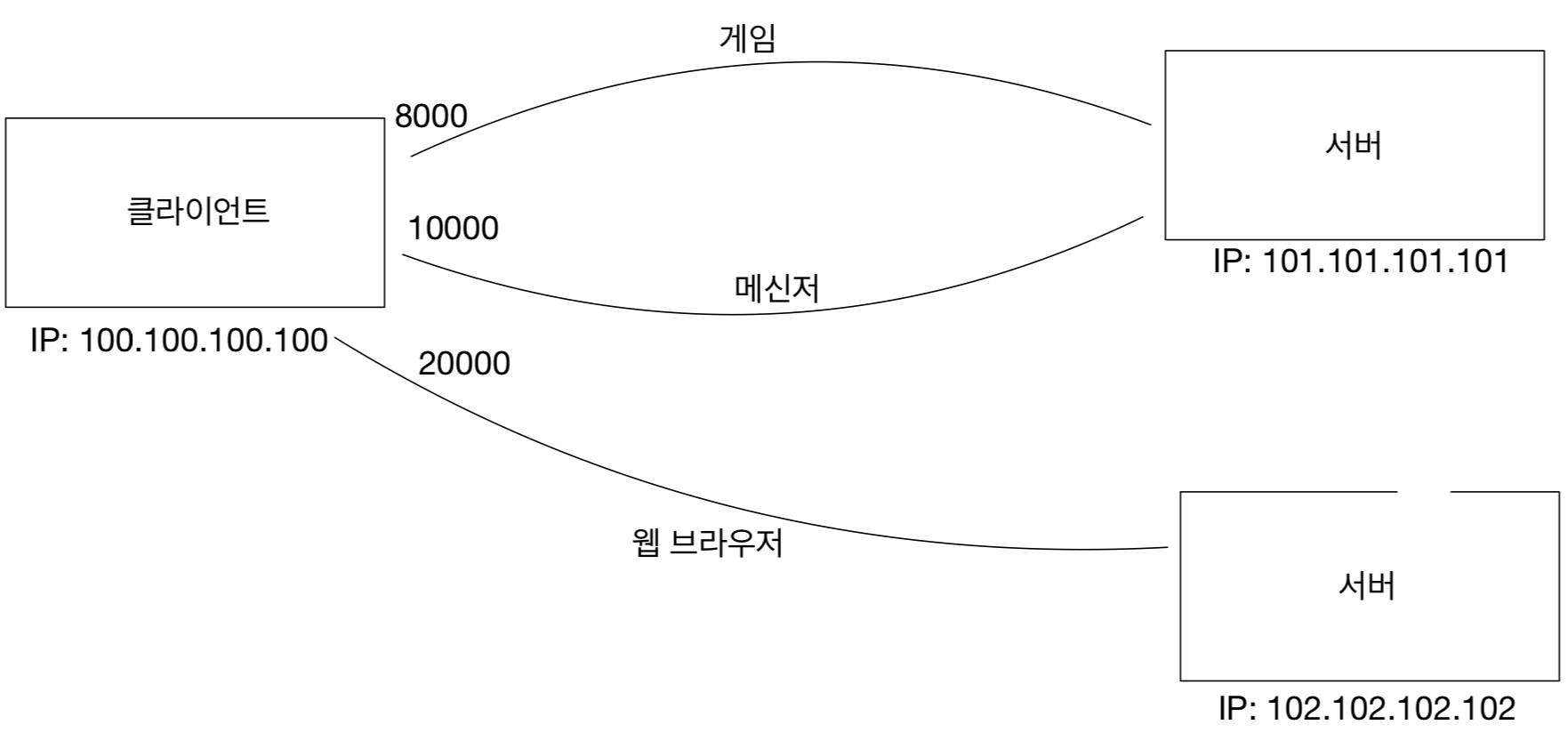
HTTP 헤더에 대해서 공부하자.
HTTP 헤더는 지금까지 나왔겠지만
해당 부분들을 말한다.
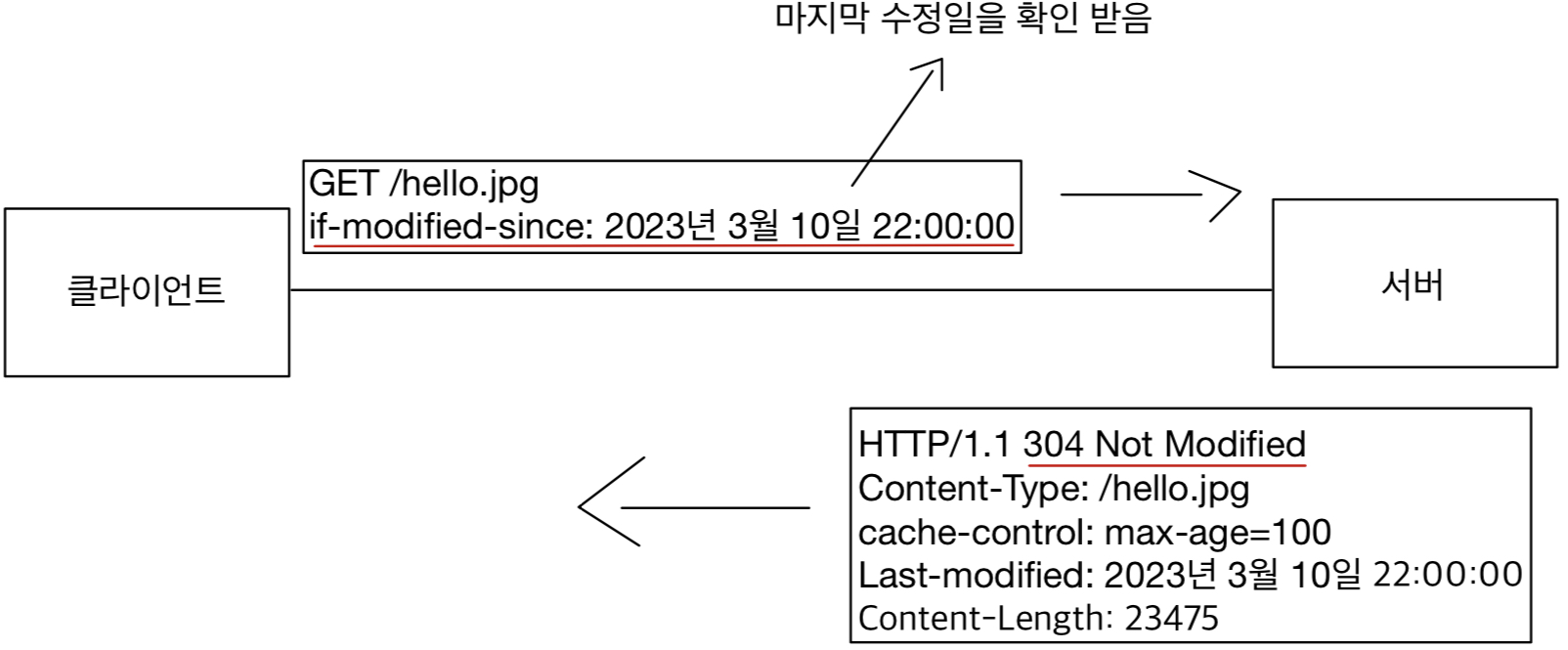
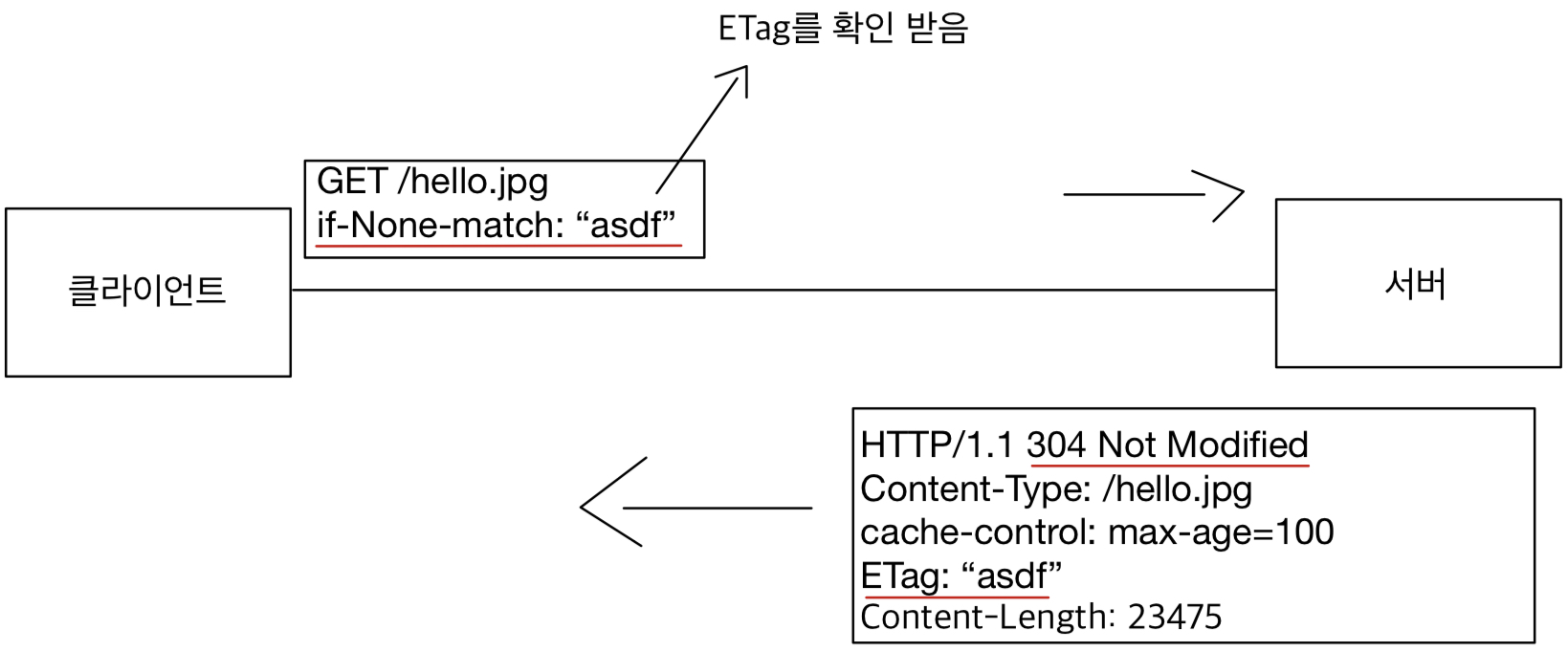
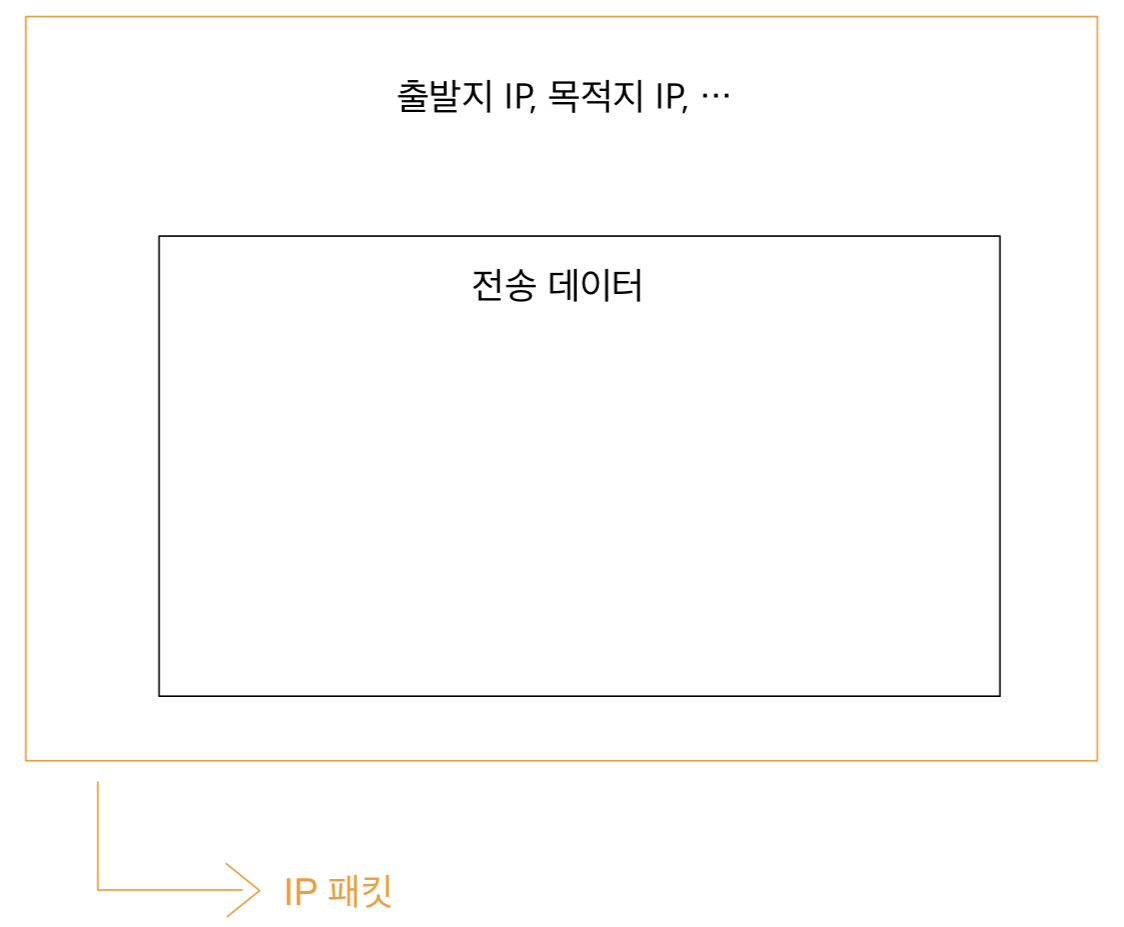
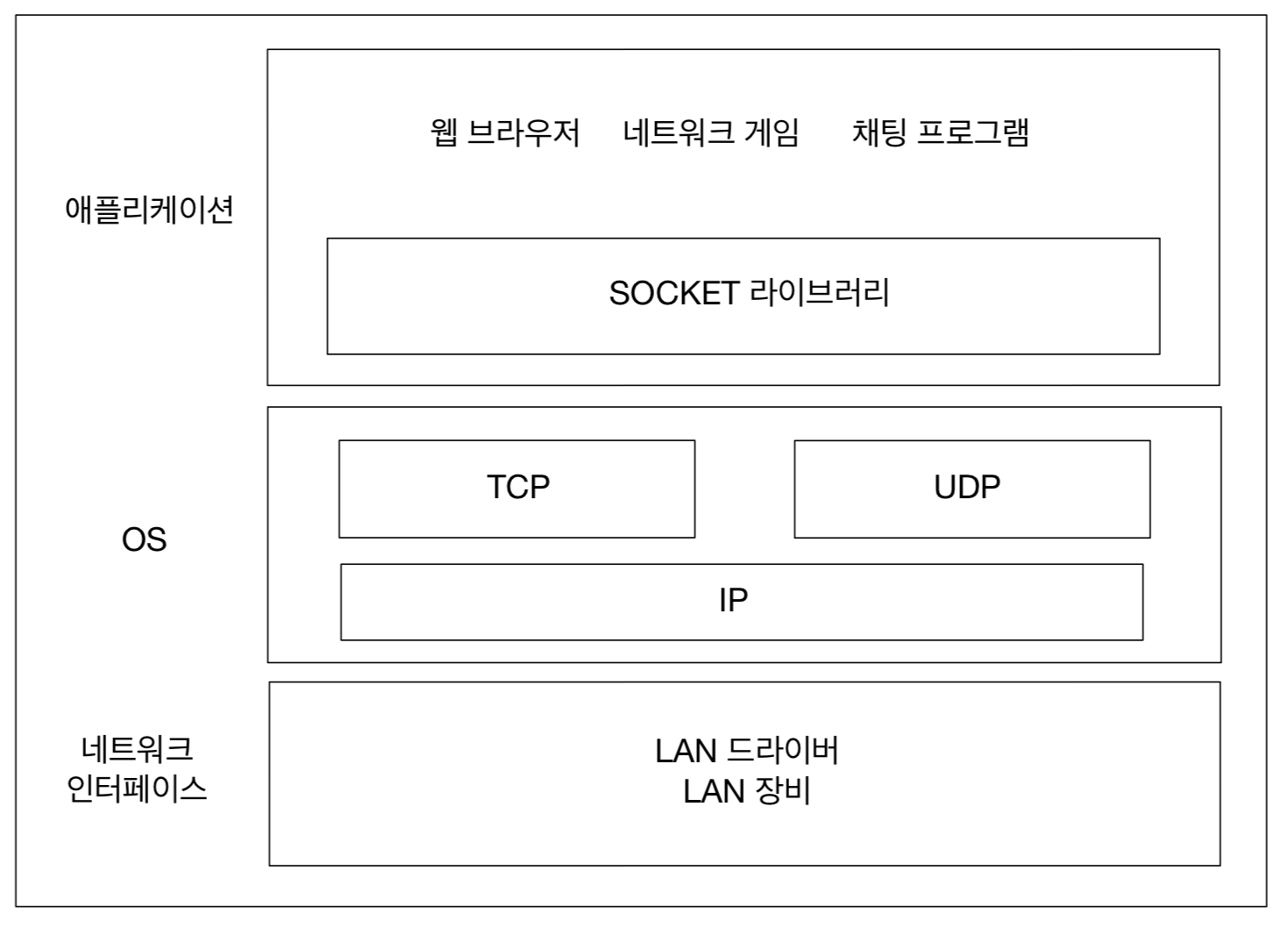
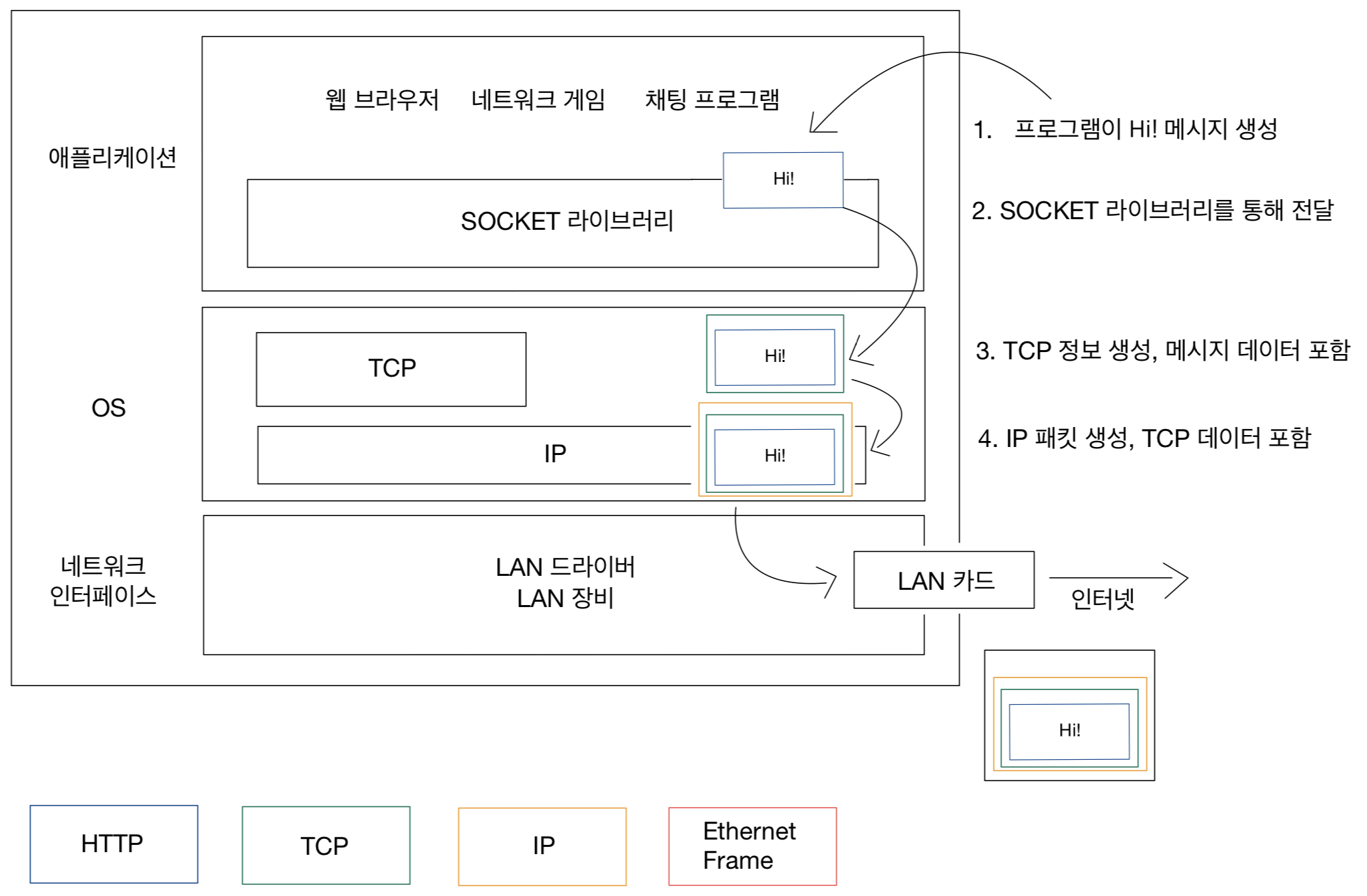
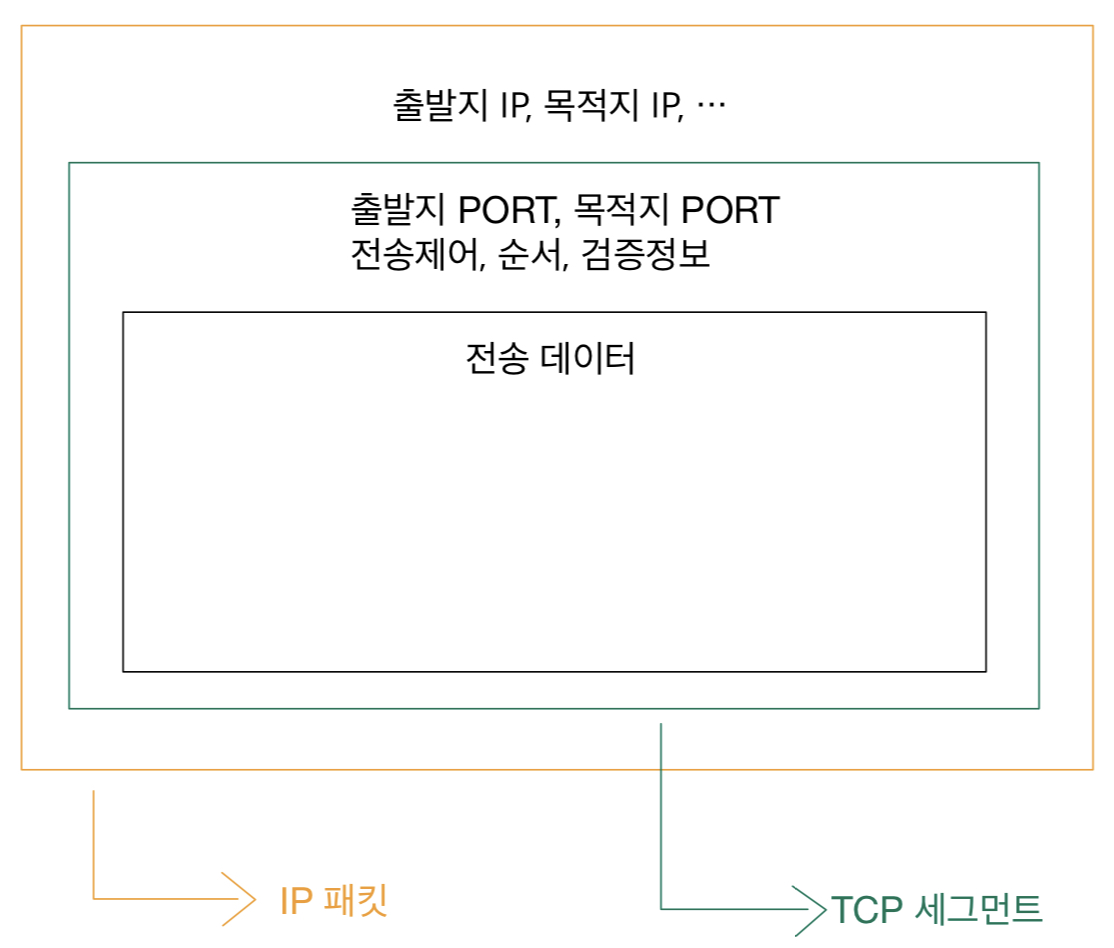
HTTP 헤더는 HTTP 전송에 필요한 모든 부가정보를 담고 있다.
헤더는 데이터를 해석할 수 있는 정보를 제공하게 되었다. (데이터 유형, 데이터 길이...)
Content-Type
표현 데이터의 형식을 담고 있다.
예로는 text/html; charset=utf-8, application/json 등이 있다.
Content-Encoding
표현 데이터를 압축하기 위해 사용한다.
데이터를 전달하는 곳에서 압축 후 인코딩 헤더를 추가한다.
예로는 gzip, deflate 등이 있다.
Content-Language
표현 데이터의 언어를 표현한다.
예로는 ko, en 등이 있다.
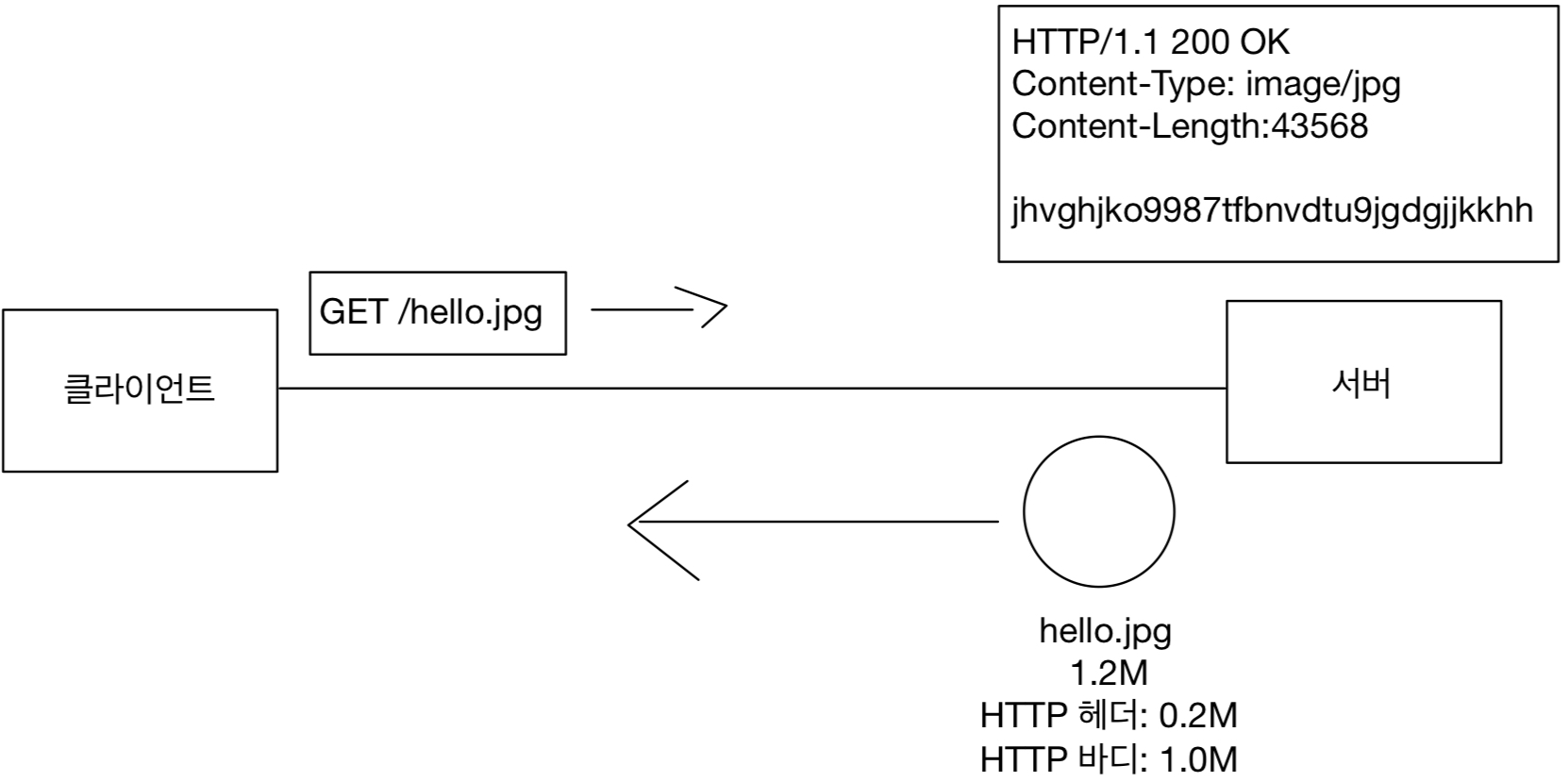
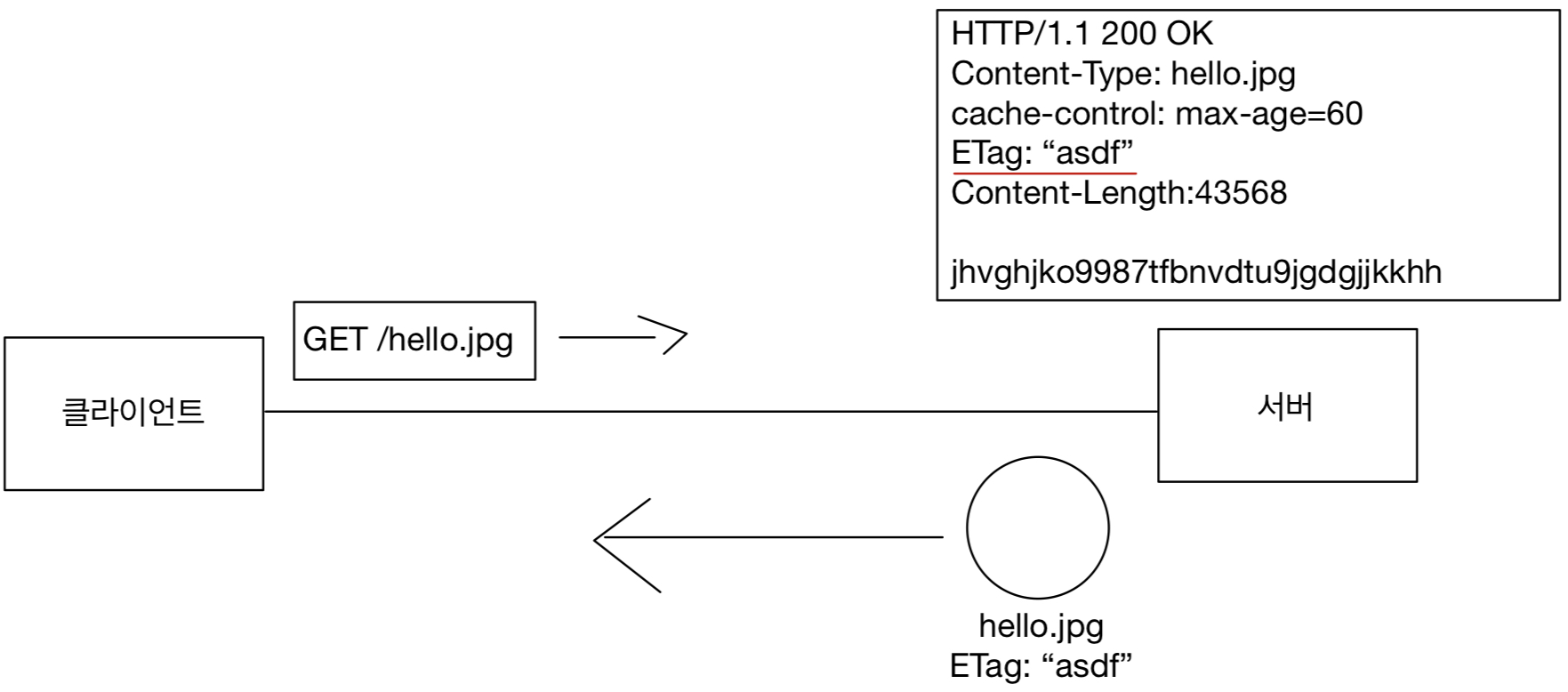
Content-Length
표현 데이터의 길이를 표현한다.
데이터는 바이트 단위로 표현한다.
클라이언트는 서버에 원하는 표현을 요청할 수 있다.
이 협상 헤더는 요청 시에만 사용할 수 있다.
Accept: 클라이언트가 선호하는 미디어 타입을 전달
Accept - Charset: 클라이언트가 선호하는 문자 인코딩을 전달
Accept - Encoding: 클라이언트가 선호하는 압축 인코딩을 전달
Accept - Language: 클라이언트가 선호하는 자연 언어를 전달
하나의 표현만 요청하는 것이 아니라 여러 개의 값들을 우선순위로 지정해 요청할 수 있다.
0 ~ 1의 값을 사용하며 클수록 높은 우선순위를 가진다. (생략하면 1)
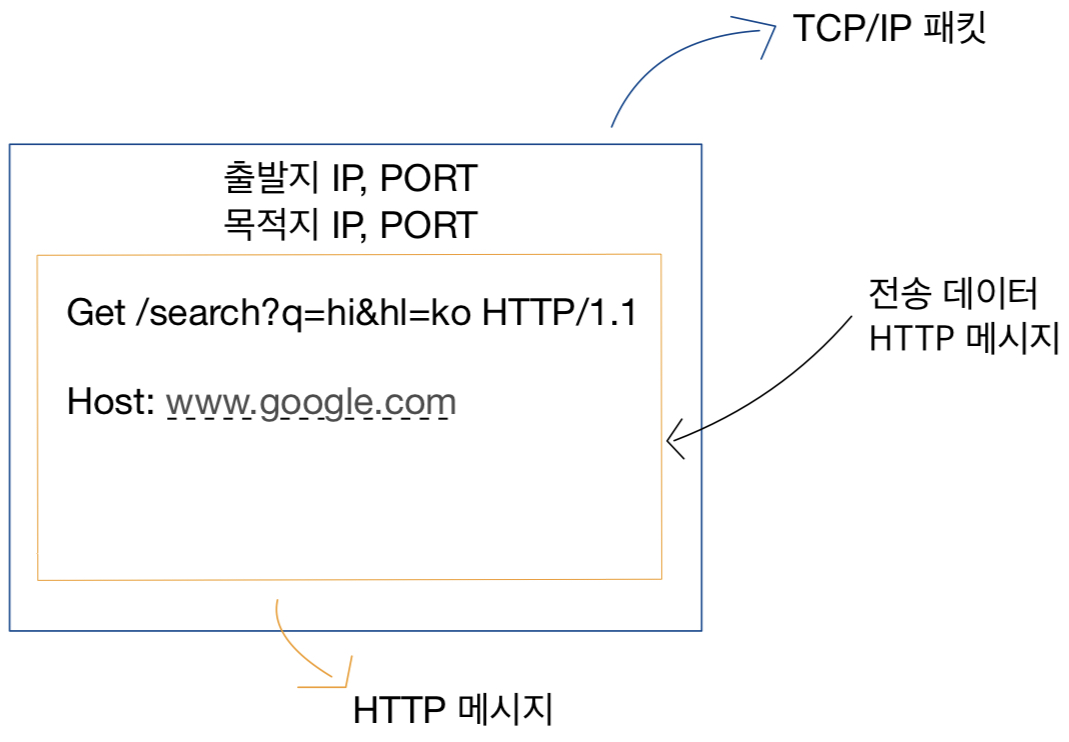
GET /page
Accept-Language: ko-KR,ko;q=0.8,en-US;q=0.8
이런 식으로 사용한다.
그리고 당연히 늘 그렇듯이 더 구체적인 코드를 우선한다.
GET /page
Accept: text/*, text/plain, */*
이렇게 되어 있다면
1. text/plain
2. text/*
3. */*
이 우선순위로 따라가게 된다.
전송 방식으로는 단순 전송, 압축 전송, 분할 전송, 범위 전송 4가지가 있다.
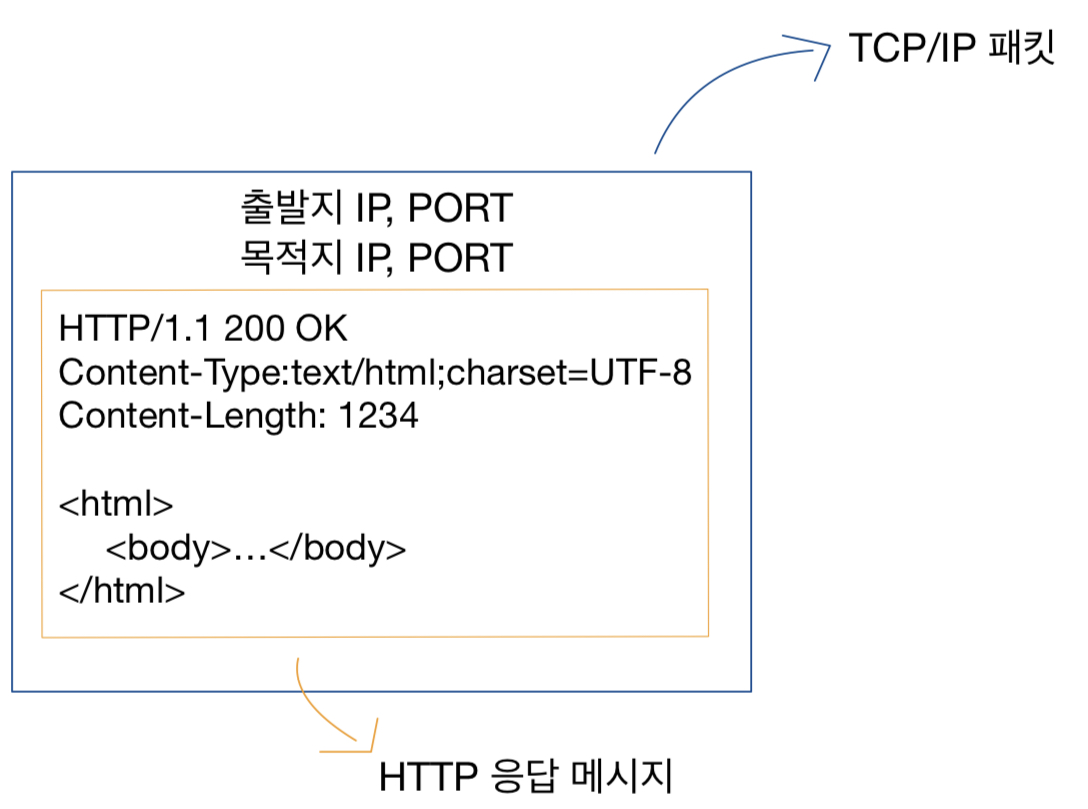
단순 전송
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Length: 3456
<html>
<body>...</body>
</html>
그냥 단순하게 이런 코드를 전송하는 것이다.
Content-Length를 적어주어야 한다.
압축 전송
HTTP/1.1 200 OK
Content-Type: text/html;charset=UTF-8
Content-Encoding: gzip
Content-Length: 521
asdfasdfgh42523yhshadsgaasdfds...
말 그대로 압축해서 보내는 것이다.
압축을 했기 때문에 Content-Encoding으로 어떻게 압축했는지 알려주어야 한다.
분할 전송
HTTP/1.1 200 OK
Content-Type: text
Transfer-Encoding: chunked
2
My
4
Name
2
is
2
sk
이렇게 하나의 데이터를 보낼 때마다 바이트 수와 분할해서 보내는 것이다.
처음부터 Content-Length로 바이트 수를 알려주면 안 된다.
범위 전송
클라이언트가 특정 범위를 요청할 때 보내는 방법으로
만약 클라이언트가
GET /page
Range: bytes=501-1000
이런 요청을 보냈다면 그 범위에 맞게
HTTP/1.1 200 OK
Content-Type: text/plain
Content-Range: byes 501-1000/1000
adsfsdafasdfasdfahsdfn
해당 범위의 데이터만 응답으로 보내는 것이다.
그냥 일반 정보로는
Form: 유저의 이메일 정보
Referer: 이전 웹 페이지 주소
User-Agent: 유저 에이전트 애플리케이션 정보
Server: 요청을 처리하는 origin 서버의 소프트웨어 정보
Date: 메시지가 생성된 날짜
가 있다.
From
요청에서 사용하며, 검색 엔진들이 주로 사용한다.
일반적으로는 많이 사용하지 않는다.
Referer
현재 요청된 페이지의 이전 웹 페이지 주소이며, 요청에서 사용한다.
Referer를 사용해서 유입 경로를 분석한다.
User-Agent
클라이언트의 애플리케이션 정보이며, 요청에서 사용한다.
어떤 종류의 브라우저에서 장애가 발생하는지 파악 가능하다.
Server
서버의 소프트웨어 정보로, 응답에서 사용한다.
Date
메시지가 발생한 날짜와 시간으로, 응답에서 사용한다.
Host: 요청한 호스트 정보
Location: 페이지 리다이렉션
Allow: 허용 가능한 HTTP 메서드
Retry-After: 유저가 다음 요청을 하기까지 기다려야 하는 시간
특별한 헤더로는 이렇게 있으며, 공통부분이 없으니 그냥 하나씩 바로 알아보자.
Host
요청한 호스트 정보를 적어주어야 해당 서버의 어떤 도메인으로 접근할 것인지를 알 수 있다.
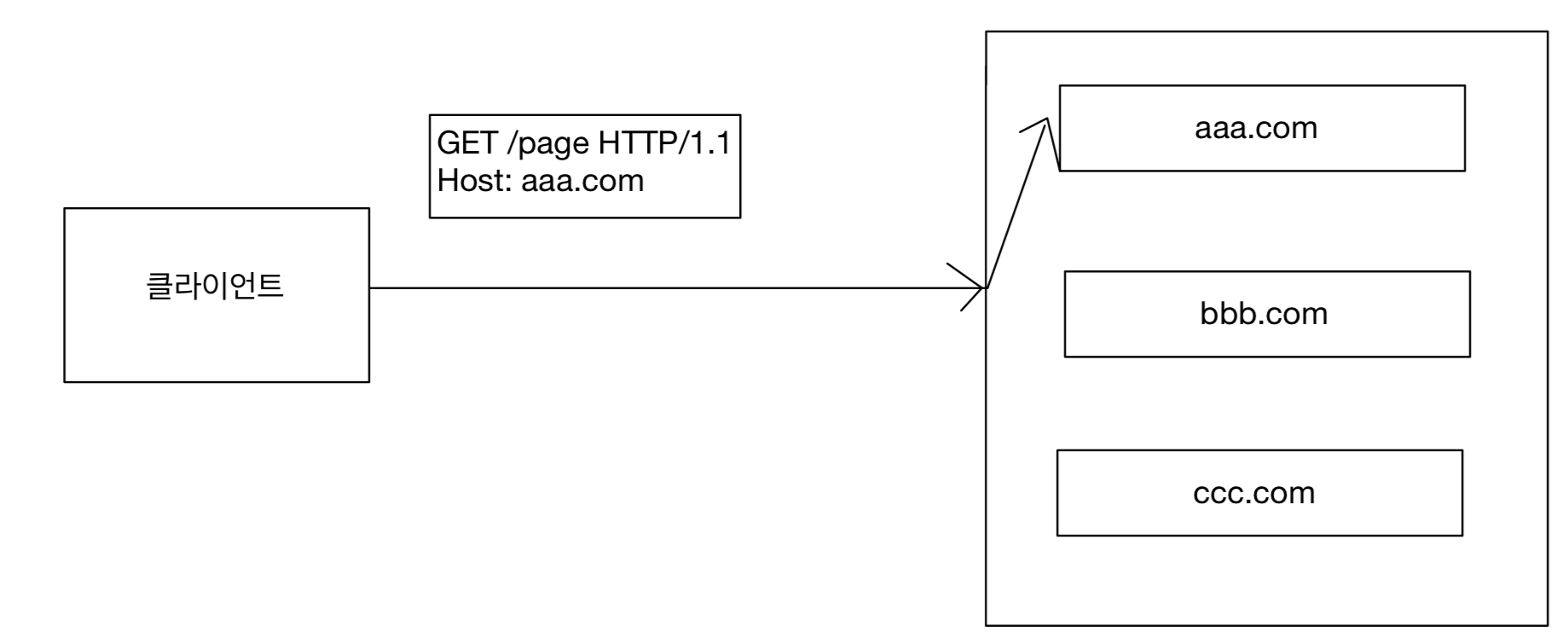
Location
페이지 리다이렉션으로 웹 브라우저는 3xx 응답의 결과에 Location 헤더가 있으면, 그 위치로 자동 이동한다.
Allow
허용 가능한 HTTP 메서드를 알려주며, 메서드 오류인 405(Method Not Allowed) 응답에 포함되어야 한다.
Retry-After
요청을 처리할 수 있는 시간을 알려주며, 503(Service Unavailable)에 포함한다.
Retry-After: Sat, 4 Dec 1999 10:12:56 GMT
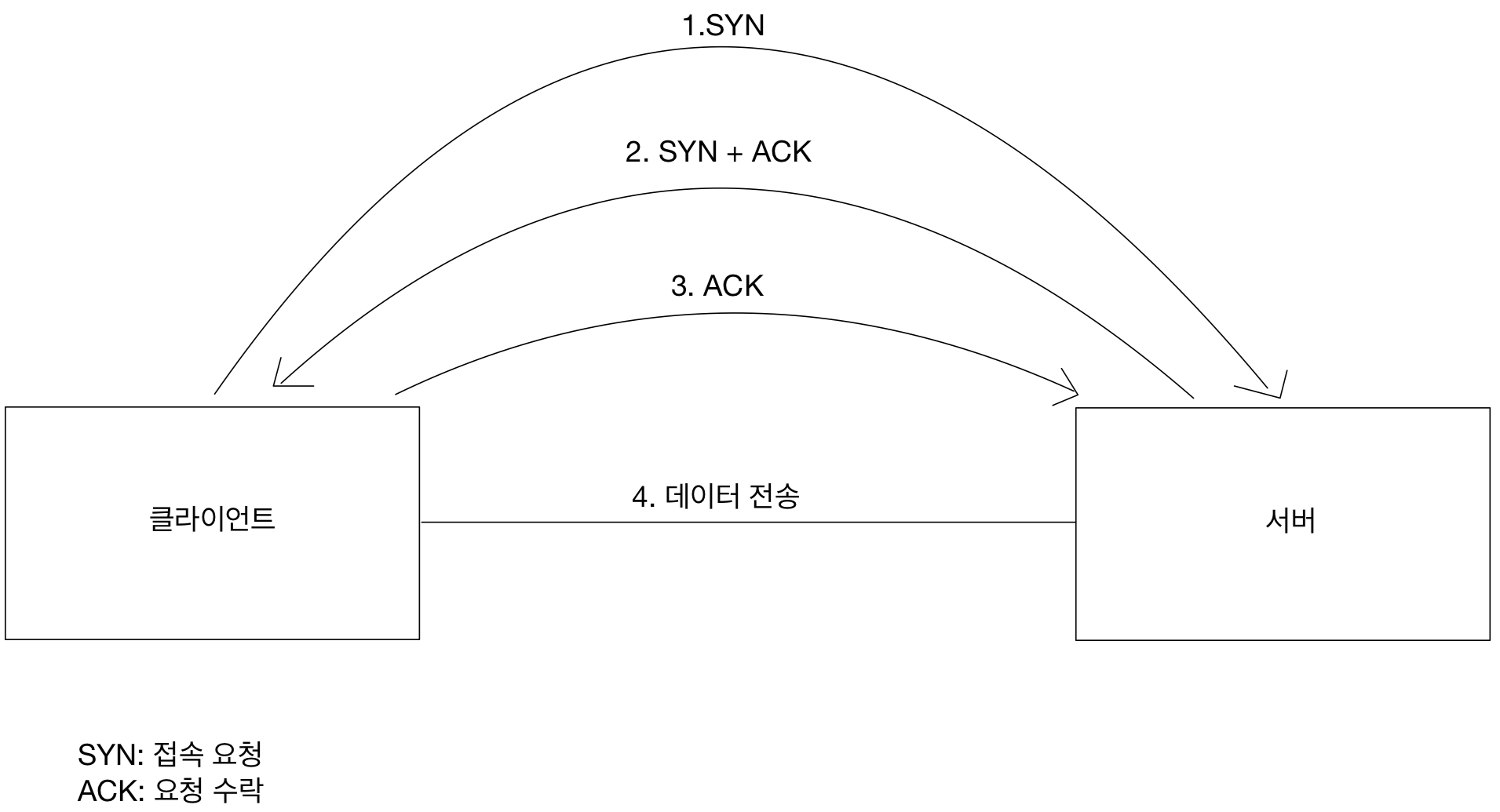
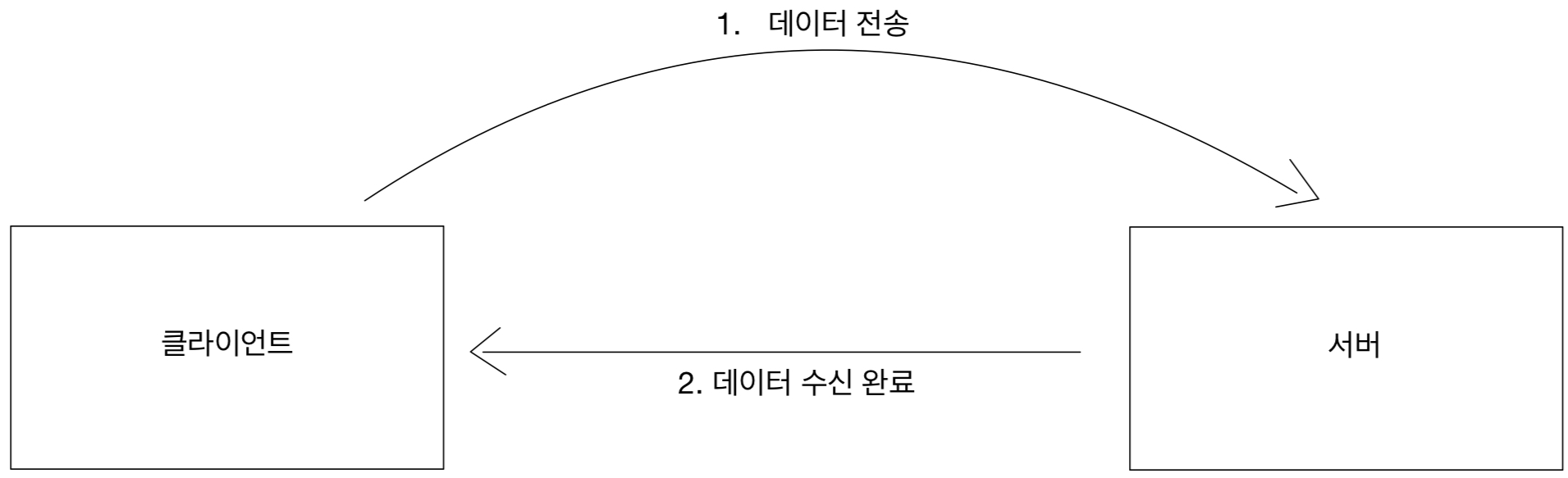
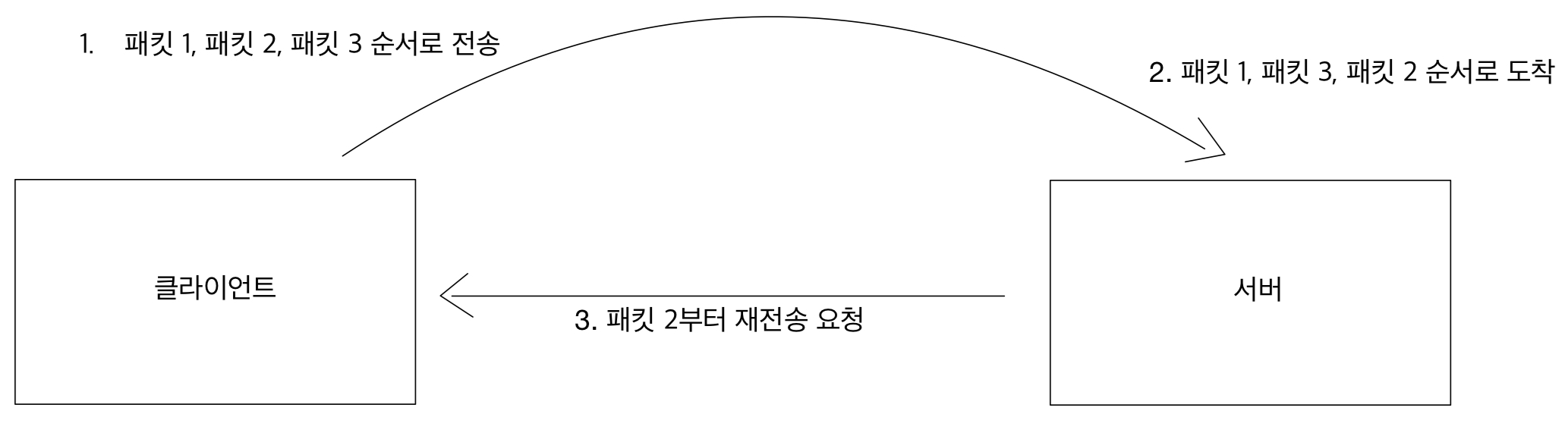
쿠키가 무엇인지는 저번 JSP 공부에서 배웠을 것이다.
만약 쿠키를 사용하지 않는다면 로그인 후 해당 도메인의 다른 페이지에 접근할 때 서버에서 유저를 기억하지 못할 것이다.
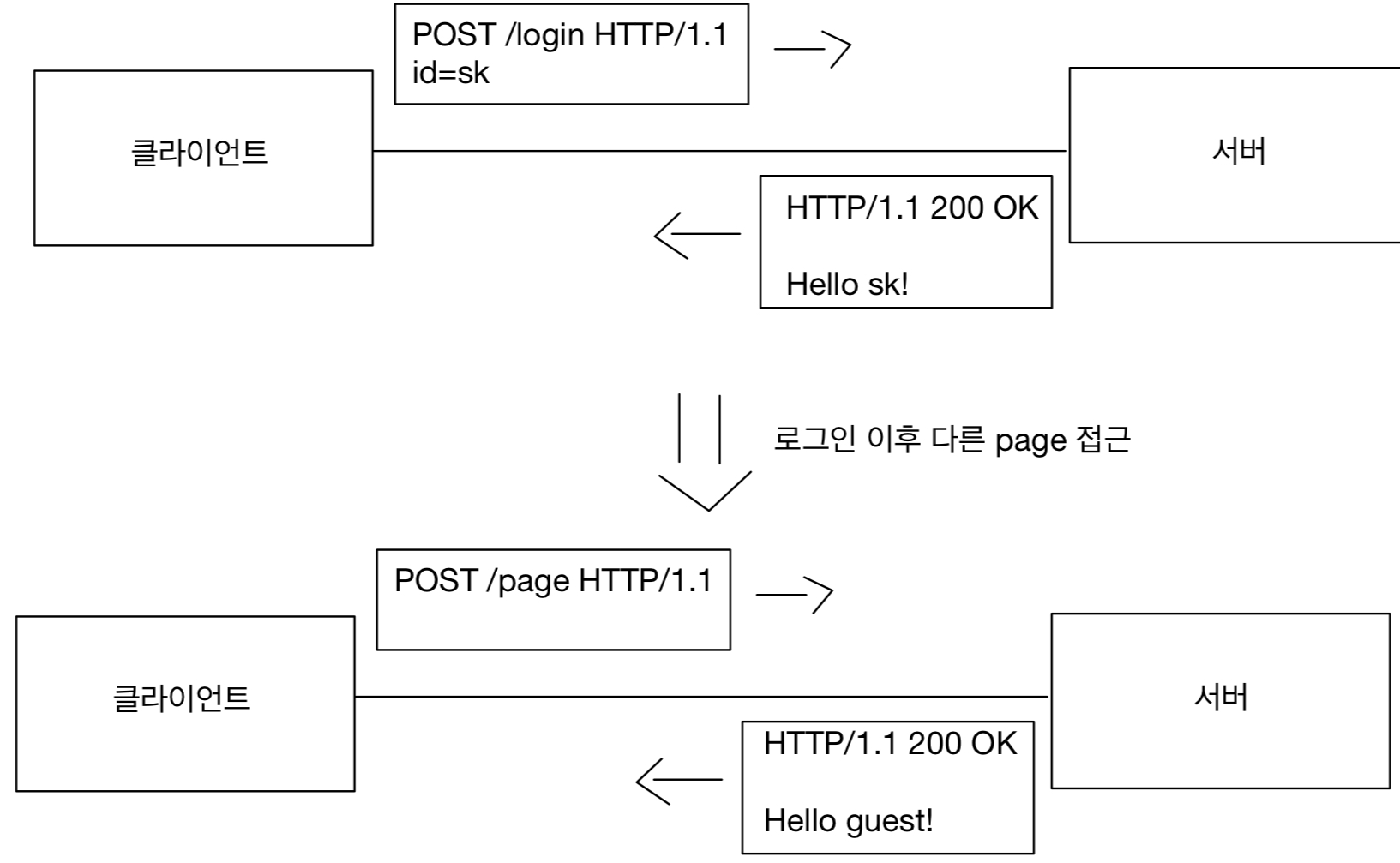
클라이언트와 서버가 요청과 응답을 주고 받으면 연결이 끊어지고, 서버는 이전 요청을 기억하지 못한다.
그렇다고 모든 GET에 사용자의 정보를 쿼리를 넘길 수도 없을 것이다.
그렇기 때문에 클라이언트에 쿠키를 남긴다.
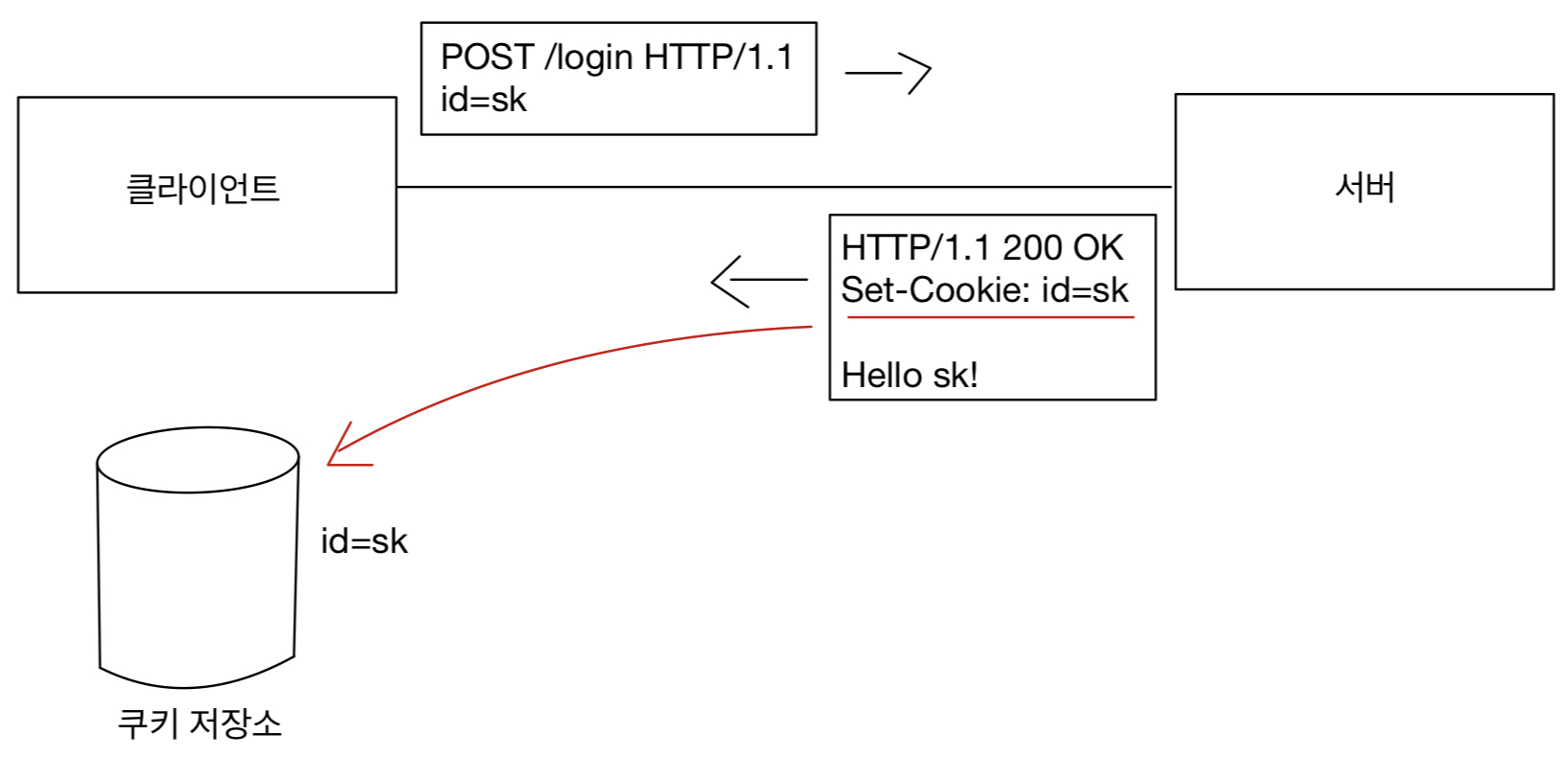
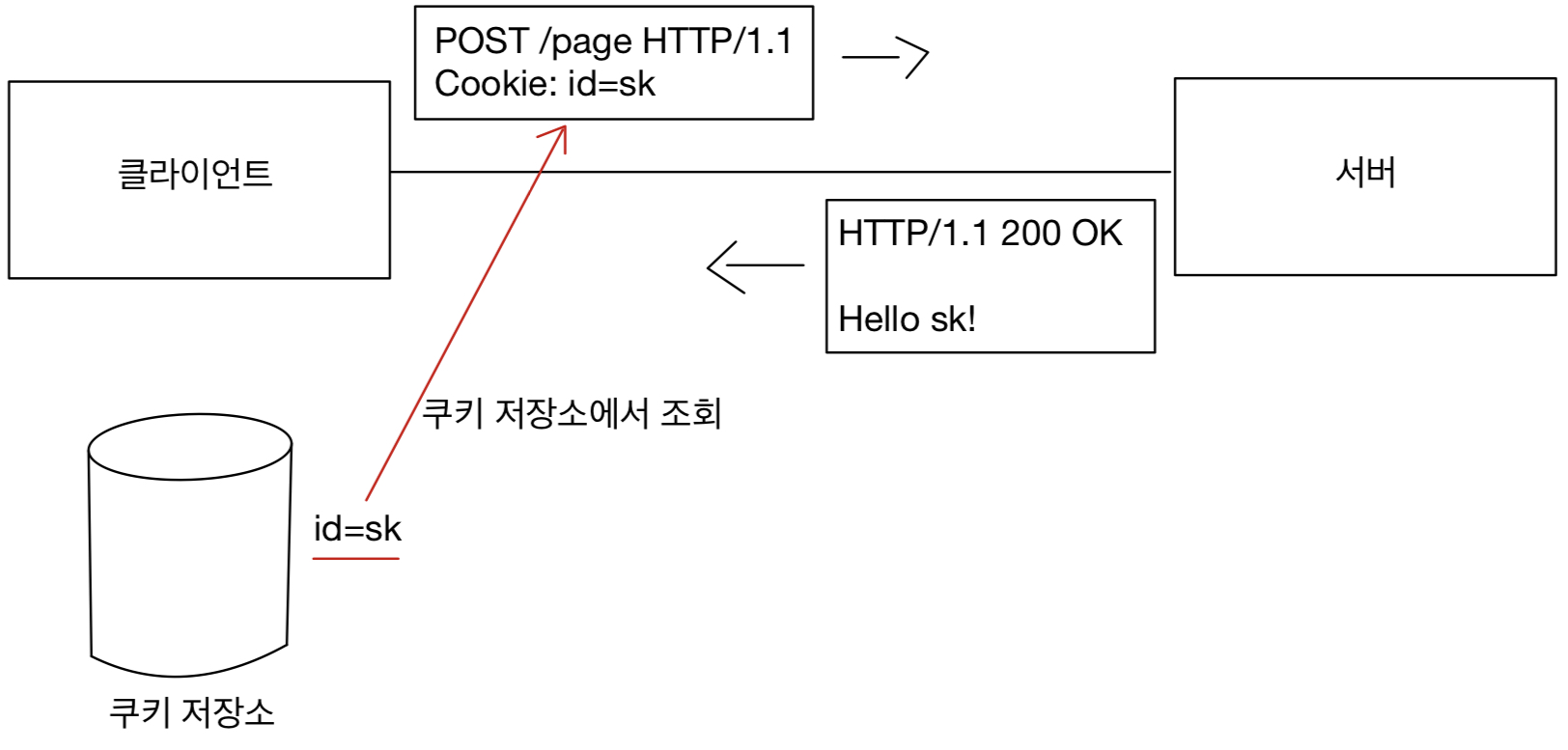
이렇게 Set-Cookie로 쿠키를 저장하고 나면 쿠키 저장소에서 조회해가며 Cookie를 이용해 헤더에 추가한다.
쿠키는 네트워크 트래픽을 추가로 유발하기 때문에 최소한의 정보만 사용하는 것이 좋다.
보안에 민감한 데이터는 저장하면 안된다.
Expries, max-age로 쿠키의 생명 주기를 설정할 수 있다.
Set-Cookie: expires=Sat, 4-Dec-1999 10:19:21 GMT
만료일이 되면 쿠키를 삭제한다.
Set-Cookie: max-age=3600
0이나 음수를 지정하면 쿠키 삭제
도메인
쿠키의 도메인을 명시한다면 명시한 문서 기준 도메인 + 서브 도메인 포함하여 쿠키가 접근한다.
쿠키의 도메인을 명시하지 않는다면 현재 문서의 도메인만 적용하여 쿠키가 접근한다.
예를 들면 domain=seungkyu.com을 지정하면
seungkyu.com은 물론이고 ???.seungkyu.com에도 쿠키가 접근한다.
하지만 생략을 한다면 seungkyu.com에만 접근하게 된다.
그리고 지정한 경로의 하위 페이지에만 쿠키가 접근하게 된다.
완성된 Set-cookie의 예를 보자면
Set-Cookie: id=1232145; expires=Sat, 4-Dec-1999 12:04:11 GMT; path=/; domain=seungkyu.com;Secure
이런식으로 작성이 되게 된다.