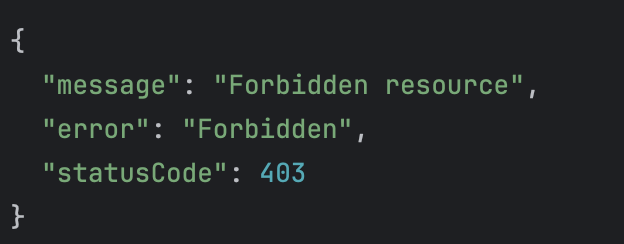
이제 저번에 만들었던 sqlService를 더 제대로 사용해보자.
XML 파일매핑
저번에 sql을 분리해서 xml에 이렇게 넣기는 했지만
사실 여기에 sql이 있는 것도 좀 아쉽다.
차라리 다른 파일에서 sql만 불러오도록 만들고 싶어진다.
JAXB를 사용하면 xml에서 정보를 가져올 수 있다고 한다.
xml에서 sql들을 가져오는 방법은 과정만 작성하도록 하겠다.
implementation("javax.xml.bind:jaxb-api:2.3.1")
runtimeOnly("org.glassfish.jaxb:jaxb-runtime:2.3.3")
implementation("javax.activation:activation:1.1.1")
이렇게 일단 xml을 읽을 수 있는 라이브러리를 가져오고
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.epril.com/sqlmap"
xmlns:tns="http://www.epril.com/sqlmap"
elementFormDefault="qualified">
<xs:element name="sqlmap">
<xs:complexType>
<xs:sequence>
<xs:element name="sql" type="tns:sqlType" maxOccurs="unbounded"/>
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:complexType name="sqlType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="key" type="xs:string" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>xsd와
<?xml version="1.0" encoding="UTF-8"?>
<sqlmap xmlns="http://www.epril.com/sqlmap">
<sql key="findAll">SELECT * FROM users</sql>
<sql key="findById">SELECT * FROM users WHERE id = ?</sql>
<sql key="insertUser">INSERT INTO users (name, email) VALUES (?, ?)</sql>
</sqlmap>xml을 작성해준다.
그리고 해당 데이터를 저장하고 있는 자바 클래스를 정의해준다.
@XmlType(name = "", propOrder = {"sql"})
@XmlRootElement(name = "sqlmap", namespace = "http://www.epril.com/sqlmap")
@XmlAccessorType(XmlAccessType.FIELD)
@Getter
@Setter
public class SqlMap {
@XmlElement(namespace = "http://www.epril.com/sqlmap", required = true)
private List<SqlType> sql;
@Override
public String toString() {
return "SqlMap{" +
"sql=" + sql +
'}';
}
}
@Setter
@Getter
@XmlAccessorType(XmlAccessType.FIELD)
@XmlType(name = "sqlType", namespace = "http://www.epril.com/sqlmap")
public class SqlType {
@XmlValue
private String value;
@XmlAttribute(name = "key", required = true)
private String key;
@Override
public String toString() {
return "SqlType{" +
"value='" + value + '\'' +
", key='" + key + '\'' +
'}';
}
}
이러고 테스트를 통해 출력해보면 다음과 같이 나오게 된다.
public class JaxbTest {
@Test
public void readSqlMap() throws JAXBException {
JAXBContext context = JAXBContext.newInstance(SqlMap.class);
Unmarshaller unmarshaller = context.createUnmarshaller();
SqlMap sqlmap = (SqlMap) unmarshaller.unmarshal(
getClass().getResourceAsStream("/sqlmap.xml")
);
System.out.println(sqlmap);
}
}
이렇게 xml에서 데이터를 가져오는 방법을 언마샬링이라고 한다고 한다.
XML 파일을 이용하는 SQL 서비스
이 sqlmap.xml을 통해서 UserDao를 사용해보도록 하자.
우선 sql을 모두 작성해준다.
<?xml version="1.0" encoding="UTF-8"?>
<sqlmap xmlns="http://www.epril.com/sqlmap"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.epril.com/sqlmap
http://www.epril.com/sqlmap/sqlmap.xsd">
<sql key="userAdd">INSERT INTO users(id, name, password, email, level, login, recommend) values(?, ?, ?, ?, ?, ?, ?)</sql>
<sql key="userGet">SELECT * FROM users WHERE Id = ?</sql>
<sql key="userGetAll">SELECT * FROM users ORDER BY ID</sql>
<sql key="userDeleteAll">DELETE FROM users</sql>
<sql key="userGetCount">SELECT COUNT(*) FROM users</sql>
<sql key="userUpdate">UPDATE users SET name = ?, password = ?, email = ?, level = ?, login = ?, recommend = ? where id = ?</sql>
</sqlmap>
이 xml을 읽어서 sql을 전달해주는 SqlService를 작성해보자.
생성자를 통해 해당 Bean이 생성되는 순간에 sqlMap을 불러와서 Map으로 저장한다.
package seungkyu;
import javax.xml.bind.JAXBContext;
import javax.xml.bind.JAXBException;
import javax.xml.bind.Unmarshaller;
import java.util.HashMap;
import java.util.Map;
public class XmlSqlService implements SqlService {
private Map<String, String> sqlMap = new HashMap<>();
public XmlSqlService() {
String contextPath = SqlMap.class.getPackage().getName();
try
{
JAXBContext jaxbContext = JAXBContext.newInstance(SqlMap.class);
Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
SqlMap sqlmap = (SqlMap) unmarshaller.unmarshal(
getClass().getResourceAsStream("/sqlmap.xml")
);
for(SqlType sqlType: sqlmap.getSql()) {
sqlMap.put(sqlType.getKey(), sqlType.getValue());
}
} catch (JAXBException e) {
throw new RuntimeException(e);
}
}
@Override
public String getSql(String key) {
String sql = sqlMap.get(key);
if(sql == null) {
throw new RuntimeException("SQL Key " + key + " not found");
}
else
return sql;
}
}이 XmlSqlService를 sqlService로 등록해준다.
빈의 초기화 작업
일단 위와 같이 만들긴 했지만, 생성하는 과정에서 몇가지 수정할 부분이 있다고 한다.
우선 생성 중 예외가 발생할 수 있고, 가져오는 파일이 sqlmap.xml로 고정이 되어있다.
우선 간단하게 파일부터 동적으로 받을 수 있도록 수정해보자.
이렇게 그냥 생성자와 빈만 수정한다.
public XmlSqlService(String fileName) {
try
{
JAXBContext jaxbContext = JAXBContext.newInstance(SqlMap.class);
Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
SqlMap sqlmap = (SqlMap) unmarshaller.unmarshal(
getClass().getResourceAsStream(fileName)
);
for(SqlType sqlType: sqlmap.getSql()) {
sqlMap.put(sqlType.getKey(), sqlType.getValue());
}
} catch (JAXBException e) {
throw new RuntimeException(e);
}
}
그리고 이 생성로직을 loadSql()로 추출하려고 하는데
public void loadSql(){
try
{
JAXBContext jaxbContext = JAXBContext.newInstance(SqlMap.class);
Unmarshaller unmarshaller = jaxbContext.createUnmarshaller();
SqlMap sqlmap = (SqlMap) unmarshaller.unmarshal(
getClass().getResourceAsStream(fileName)
);
for(SqlType sqlType: sqlmap.getSql()) {
sqlMap.put(sqlType.getKey(), sqlType.getValue());
}
} catch (JAXBException e) {
throw new RuntimeException(e);
}
}문제는 이 클래스를 스프링이 빈으로 등록해주는 것이기 때문에, 우리가 이 메서드를 호출할 방법이 없다.
그렇기에 이 클래스에 @PostConstruct를 사용하겠다.
AOP에 대해 알아볼 때, 스프링의 빈 후처리기가 있다고 했었다.
빈 후처리기는 스프링 컨테이너가 빈을 생성한 뒤에 추가적인 작업을 해줄 수 있다고 했는데, 여기서 @PostConstruct는 스프링이 DI 작업을 마친 뒤 해당 메서드를 자동으로 실행하도록 해주는 어노테이션이다.
@PostConstruct
public void loadSql(){}
이렇게 @PostConstruct 어노테이션을 붙이고
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/aop
http://www.springframework.org/schema/aop/spring-aop.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/tx
http://www.springframework.org/schema/tx/spring-tx-2.5.xsd">
<context:annotation-config/>
</beans>이렇게 어노테이션 설정을 붙여주면
이렇게 스프링을 실행하면 PostConstruct가 실행되는 것을 볼 수 있다.
스프링 컨테이너는 빈을 다음과 같은 순서로 생성한다.
변화를 위한 준비: 인터페이스 분리
솔직히 이정도면 끝났다고 생각은 했지만, 아직도 수정할 부분이 남아있다고 한다.
현재 XmlSqlService가 xml을 통해서 sql을 불러오고, 요청에 따른 sql을 반환하는 2가지의 임무를 수행하고 있다.
현재는 xml에서 map을 통해 sql을 주고 있지만, 이 방법이 엑셀로 그리고 list로 변경될 수도 있다는 것이다.
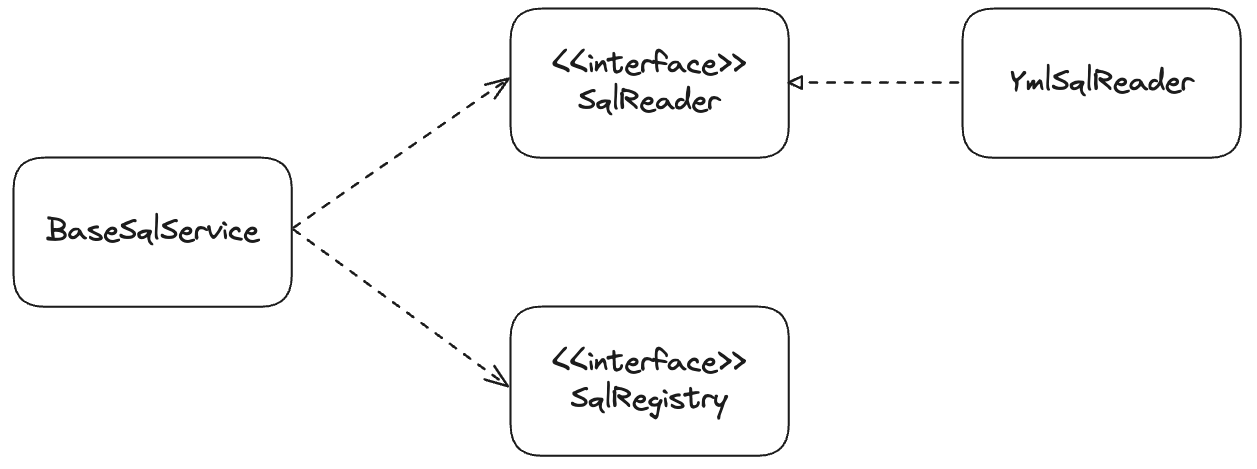
SqlService를 리펙토링하면 다음과 같은 구조로 만들어진다.
당연히 읽는 부분과 등록하는 부분은 인터페이스로 구현해야 할 것이다.
SqlService는 생성시 혹은 사용 전에 SqlReader를 통해 SqlRegistry에 sql을 등록해야 한다.
SqlService가 사실은 Sql을 이용하는 것은 아니기 때문에 Map<String, String> 타입으로 의존성이 생기게 넘겨줄 필요는 없고
SqlRegistry를 받아서 하나하나 등록해주는 방법이 더 좋다.
사실은 잘 모르겠고, 일단 만들고나서 확인해보자.
우선 각각 인터페이스부터 만들어보자.
우선 간단하게 registry부터
public interface SqlRegistry {
void registerSql(String key, String sql);
String findSql(String key);
}
그리고 Reader에서는 읽자마자 바로 넘겨주기에
public interface SqlReader {
void read(SqlRegistry sqlRegistry);
}이렇게 SqlRegistry를 넘겨주는 read 메서드 하나만 두도록 한다.
자기참조 빈으로 시작하기
이제 각각의 인터페이스를 구현해보자.
어렵게 되었지만, 결국 의존관계를 그려보면 다음과 같다.
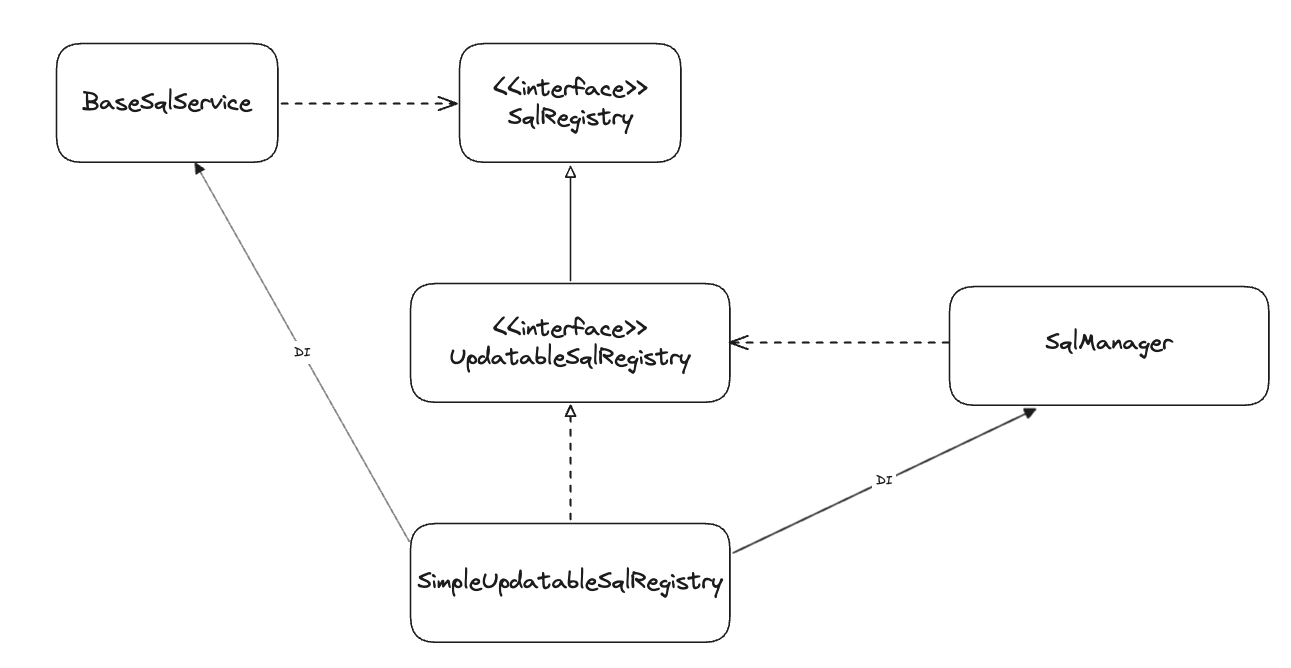
하지만 너무 구조가 복잡하기에 XmlSqlService가 다른 3개의 인터페이스를 구현하도록 만드는 방법도 있다.
그럼 구조가 다음과 같아질것이다.
사실 자기참조 빈을 사용해서 만든다고는 하는데, 이해가 잘 되지 않는다.
바로 만들어보고 생각하자.
우선 내부에서 사용할 멤버 변수를 다음과 같이 만들어준다.
@RequiredArgsConstructor
public class XmlSqlService implements SqlService, SqlRegistry, SqlReader{
@Setter
private SqlReader sqlReader;
@Setter
private SqlRegistry sqlRegistry;
private final String path;
private final Map<String, String> sqlMap = new HashMap<>();
}SqlService, SqlRegistry, SqlReader를 구현하지만 내부적으로 SqlReader와 SqlRegistry를 사용하도록 만들어준다.
@Override
public String findSql(String key) {
return sqlMap.getOrDefault(key, "NOT FOUND");
}
@Override
public void registerSql(String key, String sql) {
sqlMap.put(key, sql);
}이제 인터퍼이스들을 구현해주는데, SqlRegistry 먼저 구현해준다.
내부적으로 가지고 있는 sqlMap을 통해 간단하게 등록하고 조회한다.
@Override
public void read(SqlRegistry sqlRegistry) {
JAXBContext context;
try {
context = JAXBContext.newInstance(SqlMap.class);
} catch (JAXBException e) {
throw new RuntimeException(e);
}
Unmarshaller unmarshaller;
try {
unmarshaller = context.createUnmarshaller();
} catch (JAXBException e) {
throw new RuntimeException(e);
}
try {
SqlMap sqlmap = (SqlMap) unmarshaller.unmarshal(
getClass().getResourceAsStream(path)
);
for(SqlType sqlType : sqlmap.getSql()) {
sqlRegistry.registerSql(sqlType.getKey(), sqlType.getValue());
}
} catch (JAXBException e) {
throw new RuntimeException(e);
}
}이제는 그냥 SqlRegistry를 넘겨서 해당 인터페이스의 registrySql을 사용해 sql을 등록하도록 만든다.
이렇게 만들면 타입을 정해 SqlReader에서 SqlRegistry를 등록해줄 필요가 없어진다.
이제 SqlService는 다음과 같이 @PostConstruct와 getSql() 메서드를 구현해서 만들어준다.
@PostConstruct
public void loadSql(){
this.sqlReader.read(this.sqlRegistry);
}
public String getSql(String key){
return this.findSql(key);
}
@RequiredArgsConstructor
public class XmlSqlService implements SqlService, SqlRegistry, SqlReader{
private final SqlReader sqlReader;
private final SqlRegistry sqlRegistry;
private final String path;
private final Map<String, String> sqlMap = new HashMap<>();
@PostConstruct
public void loadSql(){
this.sqlReader.read(this.sqlRegistry);
}
public String getSql(String key){
return this.findSql(key);
}
@Override
public String findSql(String key) {
return sqlMap.getOrDefault(key, "NOT FOUND");
}
@Override
public void registerSql(String key, String sql) {
sqlMap.put(key, sql);
}
@Override
public void read(SqlRegistry sqlRegistry) {
JAXBContext context;
try {
context = JAXBContext.newInstance(SqlMap.class);
} catch (JAXBException e) {
throw new RuntimeException(e);
}
Unmarshaller unmarshaller;
try {
unmarshaller = context.createUnmarshaller();
} catch (JAXBException e) {
throw new RuntimeException(e);
}
try {
SqlMap sqlmap = (SqlMap) unmarshaller.unmarshal(
getClass().getResourceAsStream(path)
);
for(SqlType sqlType : sqlmap.getSql()) {
sqlRegistry.registerSql(sqlType.getKey(), sqlType.getValue());
}
} catch (JAXBException e) {
throw new RuntimeException(e);
}
}
}XmlSqlService는 SqlService와 SqlRegistry라는 전략을 사용하도록 구성되었기에, 이 2가지를 최대한 활용하여 만들면 된다.
사실 이게 핵심은 아니고, 이거를 xml을 통해 빈으로 등록하는 과정이 핵심이다.
<bean id="sqlService" class="seungkyu.XmlSqlService">
<constructor-arg value="/sqlmap.xml"/>
<property name="sqlReader" ref="sqlService"/>
<property name="sqlRegistry" ref="sqlService"/>
</bean>순환참조가 발생하지 않도록 setter로 자기자신을 주입해준다.
이렇게 하면 된다고는 하지만, 나는 이렇게 만들면 이해하기가 어려울 거 같아 그냥 인터페이스들을 분리하려고 한다.
<bean id="sqlReader" class="seungkyu.XmlSqlReader">
<constructor-arg value="/sqlmap.xml"/>
</bean>
<bean id="sqlRegistry" class="seungkyu.MapSqlRegistry"/>
<bean id="sqlService" class="seungkyu.XmlSqlService">
<constructor-arg ref="sqlReader"/>
<constructor-arg ref="sqlRegistry"/>
</bean>한동안 에러가 발생해서 수정했더니, 테스트를 모두 통과하는 것을 볼 수 있다.