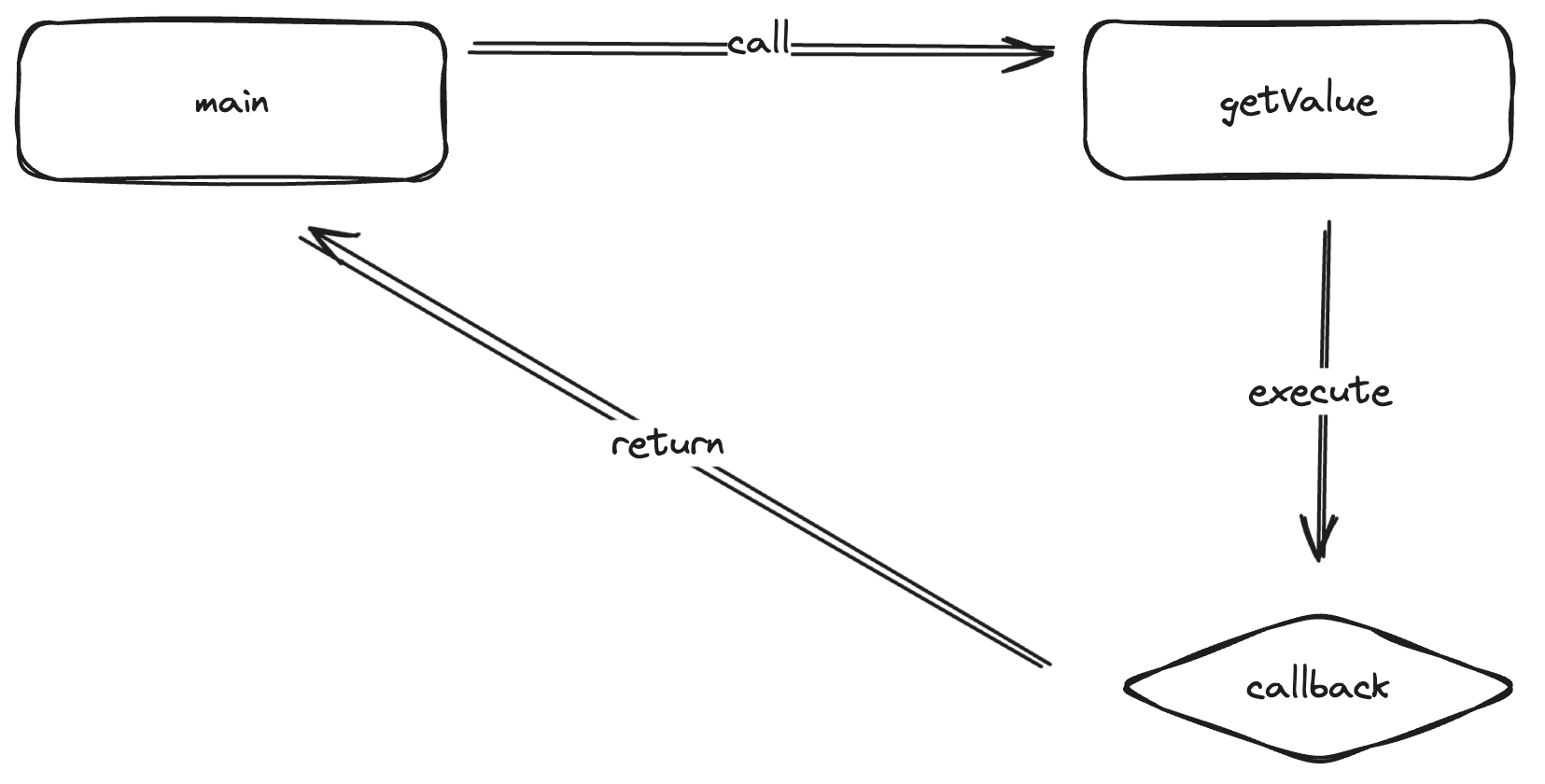
자바에서 비동기 프로그래밍을 하기 위해 알아야 하는 Future 인터페이스에 대해 알아보자.
Method reference
:: 연산자를 이용해서 함수에 대한 참조를 간결하게 포현한 것이다.
package org.example;
import java.util.function.Consumer;
import java.util.stream.Stream;
public class Main {
public static class Student {
private final String name;
public Student(String name) {
this.name = name;
}
public boolean compareTo(Student student) {
return student.name.compareTo(name) > 0;
}
public String getName() {
return name;
}
}
public static void print(String name) {
System.out.println(name);
}
public static void main(String[] args) {
var target = new Student("f");
Consumer<String> staticPrint = Main::print;
Stream.of("a", "b", "k", "z")
.map(Student::new)
.filter(target::compareTo)
.map(Student::getName)
.forEach(staticPrint);
}
}위의 코드를 예시로 들면
method reference: target::compareTo
static method reference: Main::print
instance method reference: Student::getName
constructor method reference: Student::new
이렇게 해당된다.
ExecutorService
쓰레드 풀을 이용하여 비동기적으로 작업을 실행하고 관리해준다.
쓰레드를 생성하고 관리하는 작업이 필요하지 않기 때문에, 코드를 간결하게 유지가 가능하다.
public interface ExecutorService extends Executor {
void shutdown();
<T> Future<T> submit(Callable<T> task);
void execute(Runnable command);
}이렇게 구성이 되어 있으며 각 메서드는 다음과 같이 동작한다.
execute: Runnable 인터페이스를 구현한 작업을 쓰레드 풀의 쓰레드에서 비동기적으로 실행한다.
submit: Callable 인터페이스를 구현한 작업을 쓰레드 풀에서 비동기적으로 실행하고, 해당 작업의 결과를 Future<T> 객체로 반환한다.
shutdown: ExecutorService를 종료하며, 더 이상의 task를 받지 않는다.
Executors를 사용하여 ExecutorService를 생성한다.
- newSingleThreadExecutor: 단일 쓰레드로 구성된 쓰레드 풀을 생성, 한 번에 하나의 작업만 실행
- newFixedThreadPool: 고정된 크기의 쓰레드 풀을 생성. 크기는 인자로 주어진 n과 동일
- newCachedThreadPool: 사용가능한 쓰레드가 없다면 생성, 있다면 재사용하며 쓰레드가 일정시간 사용되지 않으면 회수
- newScheduledThreadPool: 스케줄링 기능을 갖춘 고정 크기의 쓰레드 풀을 생성. 주기적이거나 지연이 발생하는 작업을 실행
- newWorkStealingPool: work steal 알고리즘을 사용하는 ForkJoinPool을 생성
Future
이제 Future 인터페이스에 대하여 자세히 살펴보자.
public interface Future<V> {
boolean cancel(boolean mayInterruptIfRunning);
boolean isCancelled();
boolean isDone();
V get() throws InterruptedException, ExecutionException;
V get(long timeout, TimeUnit unit)
throws InterruptedException, ExecutionException, TimeoutException;
}Future 인터페이스는 이렇게 구성되어 있다.
- isDone: task가 완료되었다면, true 반환
- isCancelled: task가 cancel에 의해 취소된 경우, true 반환
- get: 결과를 구할 때까지 thread가 계속 block(future가 오래 걸린다면 thread가 blocking 상태 유지), 이 문제를 해결하기 위해 timeout의 인자를 받는 메서드가 존재
- cancel: future의 작업을 취소하며, 취소할 수 없는 상황이면 false를 반환한다. mayInterruptIfRunning이 false라면 시작하지 않은 작업만 취소
이렇게 Future에 대해서 알아보았는 데, cancel로 정지시키는 거 말고는 future를 컨트롤 할 수가 없다.
또한 반환된 결과를 get으로 기다린 후 접근하기 때문에 비동기로 작업하기가 어렵다.
'백엔드 > 리액티브 프로그래밍' 카테고리의 다른 글
| CompletableFuture를 사용한 성능튜닝 (0) | 2024.03.06 |
|---|---|
| CompletableFuture 인터페이스 (1) | 2024.03.06 |
| CompletionStage 인터페이스 (1) | 2024.03.05 |
| Blocking, Non-blocking이란 무엇일까? (0) | 2024.01.08 |
| 동기, 비동기란 무엇일까? (0) | 2024.01.08 |