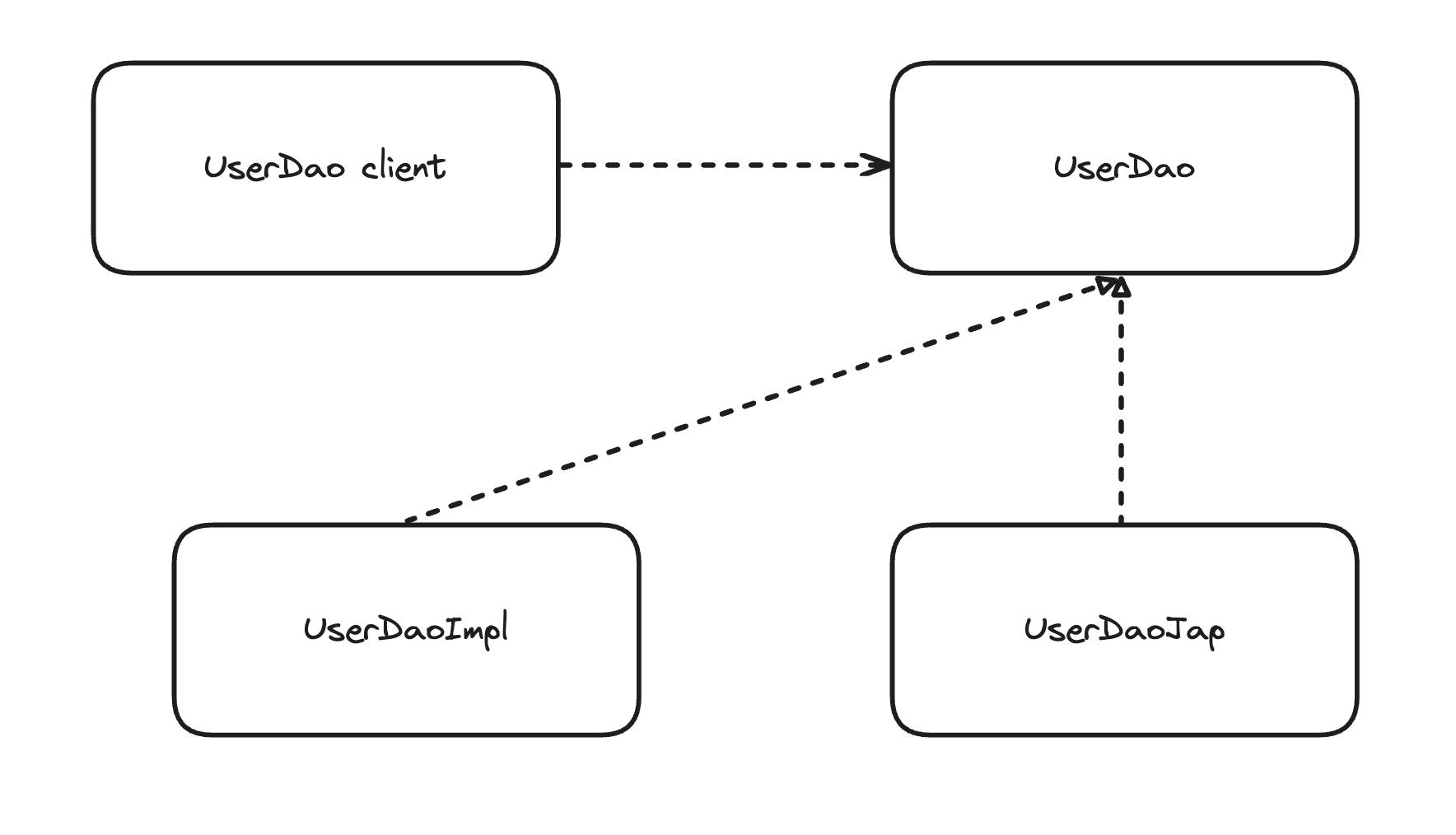
그에 비해 트랜잭션의 추상화는 애플리케이션의 비즈니스 로직과 그 하위에서 동작하는 로우레벨의 트랜잭션 기술이라는 아예 다른 계층의 특성을 갖는 코드로 분리했다.
UserService
⇢
UserDao
애플리케이션 계층
⇣
⇣
TransactionManager
⇢
DataSource
서비스 추상화 계층
⇣
⇣
JDBC, JTA, ...
기술 서비스 계층
UserService, UserDao는 애플리케이션의 로직을 담고 있는 애플리케이션 계층이다.
UserService가 UserDao를 사용하고 있으며, 인터페이스와 DI를 통해 연결되어 낮은 결합도를 가지고 있다.
또한 UserDao는 DataSource 인터페이스를 통해 추상화하여 DB를 연결하고 있기 때문에 DB 연결을 생성하는 것에 독립적이며, UserService도 PlatformTransactionManager 인터페이스를 통한 추상화 계층으로 트랜잭션 기술에 독립적이다.
이후에 변경이 되더라도 해당 기술을 사용하는 코드들은 변할 필요가 없다는 것이다.
이러한 장점이 단일 책임 원칙을 잘 지켰기에 오는 것이다.
단일 책임 원칙은 '하나의 모듈은 한 가지 책임을 가져야 한다'는 의미이다.
기존의 UserService에서는 트랜잭션을 직접 관리하고 있었다.
그리고 JDBC transaction, JTA transaction 이렇게 트랜잭션 기술을 변경 할 때마다 UserService를 수정해야 했다.
하지만 트랜잭션의 추상화를 도입하고, 트랜잭션의 이유로 UserService가 변경될 일은 없다.
지금은 현재 User와 관련된 코드만 작성이 되어 있어서, 어쩌면 이렇게 개발하는 것보다는 그냥 그때그때 바꾸는게 더 빠를 수도 있다.
트랜잭션을 TransactionSynchronizationManager에 등록하는 작업을 수행하기에 JdbcTemplate이 여기서 가져다가 쓰는 것이다.
이렇게 새로 생성하던 JtaTransactionManager도 생성자를 통해 주입받도록 하자.
@RequiredArgsConstructor
public class UserServiceImpl implements UserService{
private final UserDao userDao;
private final PlatformTransactionManager transactionManager;
}
public void upgradeLevels() {
for(User user : userDao.getAll())
{
if(user.isUpgradeLevel())
upgradeLevel(user);
}
}
해당 메서드를 User로 옮기고 이렇게 수정해줬다.
User의 테스트도 만들어보자.
테스트는 어차피 꾸준하게 사용하니, 간단하더라도 추가해두는 것이 좋다.
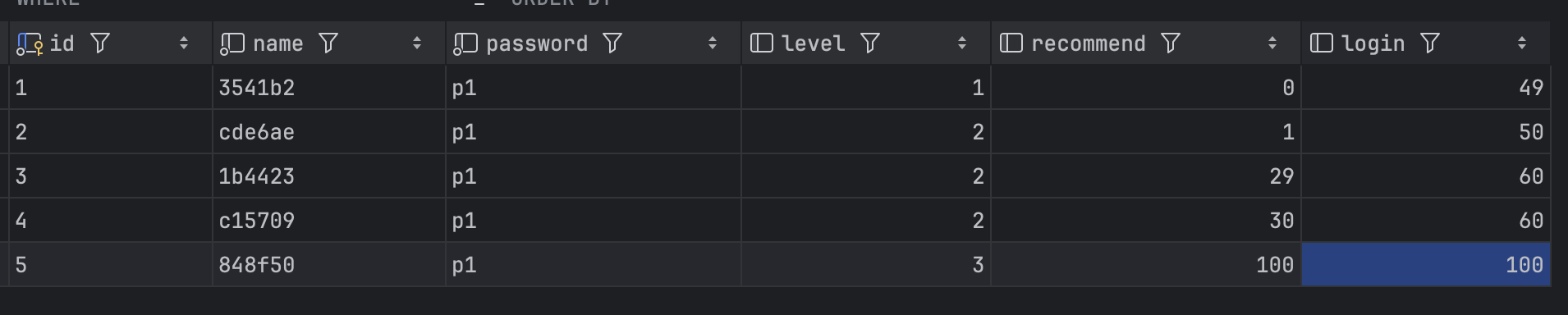
class UserTest {
private User user;
@BeforeEach
void setUp() {
user = User.builder()
.id(UUID.randomUUID().toString().substring(0, 8))
.name("seungkyu")
.password("123456")
.login(1)
.recommend(2)
.level(Level.BRONZE)
.build();
}
@Test
public void upgradeLevelTest(){
user.upgradeLevel();
Assertions.assertEquals(Level.SILVER, user.getLevel());
}
}
User는 스프링 빈이 아니기 때문에 SpringExtension을 추가해주지 않아도 괜찮다.
또한 User로 다시 돌아가보자.
public boolean isUpgradeLevel() {
Level level = this.level;
return switch (level) {
case BRONZE -> this.login >= 50;
case SILVER -> this.recommend >= 30;
case GOLD -> false;
};
}
지금은 조건을 이렇게 50, 30과 같은 수로 나타내고 있다.
하지만 나중에 변경될 수도 있으며, 이 조건을 외부에서 사용할 경우도 있을 것이다.
그렇기에 이렇게 숫자로 나타내는 것이 아닌 상수로 만들어주는 것이 좋다.
해당 조건의 값
public class UserServiceImpl implements UserService{
public static final int SILVER_LOGIN_COUNT = 50;
public static final int GOLD_RECOMMEND_COUNT = 30;
}
은 비즈니스 로직에 있는것이 맞다고 생각하여 UserService에 상수로 선언하였다.
그리고 User 클래스에서 값들에 맞추어 코드를 변경해준다.
public boolean isUpgradeLevel() {
Level level = this.level;
return switch (level) {
case BRONZE -> this.login >= SILVER_LOGIN_COUNT;
case SILVER -> this.recommend >= GOLD_RECOMMEND_COUNT;
case GOLD -> false;
};
}
JDBC는 데이터베이스에 접근하여 데이터를 가져오고 수정할 수 있기에 자바의 가장 많이 사용되는 API 중 하나라고 한다.
//MSSQL
SELECT TOP 5 * FROM USERS;
//MYSQL
SELECT * FROM USERS LIMIT 5;
하지만 이렇게 SQL 중에서도 Database마다 다른 문법이 존재한다. 그럼 우리가 만든 UserDao는 MySQL이라는 데이터베이스에 종속되어 버리며, 다른 데이터베이스로 전환은 거의 불가능해진다. 그리고 여기서 발생하는 SQLException의 에러 정보도 DB마다 다르다.
이런 코드가 있다면 MySQL 전용코드가 되어버리기에 여기에서도 MySQL에 종속되는 것이다. 만약 데이터베이스가 MySQL에서 MSSQL로 바뀐다면 현재 사용하는 query도 사용하지 못하고, 에러코드도 제대로 동작하지 못하는 것이다.
그렇기에 SQLException은 예외가 발생한 경우 DB의 상태 정보를 가져올 수 있도록 한다. getSQLState() 메서드를 통해 상태정보를 가져올 수 있도록 한다. 이때는 DB별로 다른 에러 코드를 통합하기 위해, Open Group의 XOPEN SQL 스펙의 SQL 상태코드를 따르도록 한다고 한다.
DB 에러 코드 매핑을 통한 전환
사용하는 DB를 바꾸더라도, 에러코드를 바꾸지 않으려면 이런 에러코드를 원하는 에러로 가져올 수 있도록 해야한다. 그렇기에 DB별 에러 코드를 참고해서 원하는 예외로 바꾸어야 하는 것이다.
오라클에서 PK 중복으로 발생하는 에러코드는 1이다.
이 에러코드를 duplicateKeyCodes로 변경해야 하는 것이다.
그렇기에 이런 에러 코드를 스프링의 예외 클래스로 매핑할 수 있도록 xml 파일을 작성할 수 있다.
이전에는 jdbcTemplate으로 쿼리를 교체 했었는데, 의도하지 않았지만 같이 달라진 부분이 있다.
바로 throws에 던지는 예외들이 사라졌다.
기존에는
public void deleteAll() throws SQLException{
jdbcContext.executeSql("delete from users");
}
이렇게 작성했지만
지금은
public void deleteAll(){
jdbcTemplate.update("delete from users");
}
이렇게 throws가 사라진 것을 볼 수 있다.
예외의 종류와 특징
자바에서 예외는 크게 3가지라고 한다.
Error
주로 JVM에서 발생하는 에러이기에 애플리케이션 코드로 잡을 수는 없다.
이 예외는 처리할 필요도 할 수도 없다고 한다.
Exception과 체크 예외
java.lang.Exception을 상속받아 만든 클래스들이다. 개발자가 작성한 애플리케이션 코드에서 예외가 발생했음을 알리는 것이며 Exception 클래스는 다시 체크 예외와 언체크 예외로 구분된다. 체크 예외는 RuntimeException을 상속받지 않은 클래스, 언체크 예외는 RuntimeException을 상속받은 클래스이다. 체크 예외가 발생할 수 있는 메서드를 사용하면 catch로 감싸던지, throws로 밖에 던지든지 해야한다.
RuntimeException과 언체크 예외
java.lang.RuntimeException 클래스를 상속한 예외들은 명시적인 예외처리를 강제하지 않기 때문에 언체크 예외라고 불린다. 주로 프로그램의 오류가 있을 때 발생하도록 의도되었으며, NullPointerException이 해당된다.
예외처리 방법
이렇게 예외의 종류를 알아보았으니, 예외를 처리하는 방법들에 대하여 알아보자.
크게 3가지가 존재한다.
예외 복구
예외의 상황을 파악하고, 문제를 해결해서 돌려놓는 것이다.
만약 데이터베이스에 접근해야 하는데, 네트워크 관련으로 문제가 발생한다. 이런 경우에 예외 처리 부분에서 직접 연결의 재시도를 수행한다면, 이것은 예외 복구에 해당하는 것이다. 물론 일정한 횟수까지만 재시도를 시도해야 한다.
예외처리 회피
예외처리를 자신이 담당하지 않고, 자신을 호출한 쪽으로 던져버리는 것이다. 물론 무책임하게 계속 상위 메서드로 보내라는 것이 아니다. JdbcTemplate도 SQLException을 거기서 처리하지 않고 던져주고 있다. 템플릿에서 처리할 문제가 아니라고 생각하기 때문이다. 무조건 발생한 곳에서 처리하는 것이 아닌, 상위 메서드로 보내서 적절한 곳에서 처리하는 것도 좋은 방법이다.
예외 전환
예외를 회피하기보다 다른 예외로 전환하는 방식이다.
사용하는 이유는 크게 2가지이다. 첫째는 해당 예외 상황을 더 자세하게 말해주도록 커스텀 예외를 만들어서 전환하는 경우, 둘째는 체크 예외를 언체크 예외르 바꾸는 경우에 사용한다.
대부분 서버에서는 처리되지 않은 예외를 일괄적으로 다룰 수 있는 기능을 제공한다. 이렇게 처리되지 못한 에러들을 관리자에게 메일로 통보해주고, 사용자에게 에러메시지를 적절하게 보여주는 것이 가장 바람직한 방법이다.
예외처리 전략
사실 지금까지 계속 자바의 예외에 대하여 공부하고 있지만, 사실 이 자바를 스프링에서 사용하기 위함이었다. 스프링은 보통 하나의 요청에 대해 하나의 응답을 주고 있는데, 이 중간에 에러가 발생해도 사용자와 상호작용이 불가능하다. 그렇기에 사실상 대부분의 예외가 처리가 불가능하기에 체크 예외가 굳이 필요하지 않다는 것이다. 차라리 그런 예외 상황을 만들지 않는 것이 더 중요하다고 한다. 어쩌면 언체크 예외로 한번에 처리하는 것이 더 좋을 수도 있다.
여기 수정된 add() 메서드를 보면 DuplicatedUserIdException, SQLException 두 가지의 예외를 던지고 있다.
중복이 발생한 경우에는 DuplicatedUserIdException이 더 명확한 의미를 지니기에 해당 예외로 전환했다.
그리고 DuplicatedUserIdException은 복구가 가능하지만, SQLException은 보통 복구가 불가능하기에 런타임 예외로 그냥 던져버리는게 나을 수도 있다.
그렇기에 예외처리 전략을 수정해서 다음과 같이 바꿀 수 있다.
public void add(User user) throws DuplicateUserIdException{
try{
//
}
catch (SQLException e){
if(e.getErrorCode() == MysqlErrorNumbers.ER_DUP_ENTRY)
throw new DuplicateUserIdException(e);
else
throw new RuntimeException(e);
}
}
의미를 가지는 DuplicateUserIdException을 제외하고는 언체크 예외가 되었다.
이제 add()를 사용하는 곳에서는 더 이상 불필요하게 SQLException을 처리할 필요가 없으며 DuplicateUserIdException은 핸들링 할 수 있다.
이렇게 복구할 수 없다고 생각하고 그냥 낙관적으로 생각해버리는 것이 런타임 예외 중심 전략이다. 반면에 시스템 또는 외부의 예외상황이 원인이 아니라 애플리케이션 자체의 로직에서 발생시키고, catch 하도록 바라는 것이 있다. 이런 예외들은 애플리케이션 예외라고 한다. 이런 예외들은 if문보다 더 명확하게 해당 로직을 처리하도록 개발자에게 강요한다.
SQLException은 어떻게 되었나?
이제는 알 수 있을 것이다.
왜 SQLException을 처리할 필요가 없어졌는지
우선 SQLException은 Exception으로 체크 예외이다.
jdbcTemplate에서는 이러한 SQLException을
이렇게 잡아서 DataAccessException으로 처리하고 있다.
DataAccessException은
RuntimeException이기 때문에, 언체크 예외로 전환된 것을 알 수 있다.
대부분의 경우 SQLException은 복구가 불가능하다.
네트워크와 관련된 부분을 로직에서 어떻게 처리하겠는가?
그렇기에 로직에서 수정 가능한 DataAccessException만 처리하도록 하고, 나머지는 그냥 모두 포기한 것이다.
이렇게 Create, Update, Delete와 같이 데이터베이스의 정보가 변경되는 쿼리는 update를 통해 작성해주면 된다.
이제는 정보를 가져오는 쿼리를 작성해보자.
getCount()는 유저의 수를 가져오는 메서드였다.
수를 가져오는 쿼리는 간단하게 queryForObject()를 사용한다.
쿼리를 작성하고, 원하는 타입을 지정해주면 된다.
public int getCount() {
Integer result = jdbcTemplate.queryForObject("select count(*) from users", Integer.class);
return result == null ? 0 : result;
}
이 방법으로 user의 정보 또한 읽어올 수 있다.
public User get(String id){
return jdbcTemplate.queryForObject(
"select * from users where id = ?", (rs, rowNum) -> new User(
rs.getString("id"),
rs.getString("name"),
rs.getString("password")
), id);
}
엄청 간단해진 get() 메서드이다.
RowMapper를 상속받아서 mapRow() 메서드를 구현해야 하지만, 이 부분도 lambda로 간단하게 작성했다.
대신 queryForObject는 하나의 row만 가져오기 때문에, 해당하는 row가 없는 경우에도 에러가 발생한다.
그 때 발생하는 에러가 EmptyResultDataAccessException이기 때문에, 해당 에러를 핸들링하며 개발하면 된다.
다음 row를 가져오고 싶다면 rs.next()를 호출해가며 다음 값을 읽어오면 된다.
그러면 리스트로 user들을 조회하는 메서드를 만들어보자.
일단 TDD 느낌으로 테스트를 먼저 만들어보면
@Test
public void getAll() throws SQLException {
User user1 = new User("user1", "user1", "pw1");
User user2 = new User("user2", "user2", "pw2");
userDao.deleteAll();
userDao.add(user1);
List<User> users1 = userDao.getAll();
Assertions.assertEquals(1, users1.size());
Assertions.assertEquals(user1, users1.get(0));
userDao.add(user2);
List<User> users2 = userDao.getAll();
Assertions.assertEquals(2, users2.size());
Assertions.assertEquals(user1, users2.get(0));
Assertions.assertEquals(user2, users2.get(1));
}
그리고는 getAll() 메서드를 다음과 같이 작성해준다.
public List<User> getAll() {
return this.jdbcTemplate.query(
"SELECT * FROM users ORDER BY id",
(rs, rowNum) ->
new User(rs.getString("id"), rs.getString("name"), rs.getString("password"))
);
}
query() 메서드를 사용해 값을 가져온다.
query()는 여러 개의 로우가 결과로 나오는 일반적인 경우에 사용한다.
그렇기 때문에 리턴 타입은 List<T>이다.
query()를 사용하면 next를 사용하지 않아도, 로우의 개수만큼 RowMapper 콜백으로 데이터를 mapping 해준다.
이렇게 작성하고 테스트를 실행하면 깔끔하게 성공하는 것을 볼 수 있다.
이렇게하면 끝나지만 이 책에서는 항상 예외적인 상황까지 생각해보라고 말한다.
데이터베이스가 빈 경우에는 과연 null이 리턴될까? 빈 list가 리턴될까?의 질문이다.
package seungkyu;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.PreparedStatementCreator;
import org.springframework.lang.NonNullApi;
import javax.sql.DataSource;
import java.sql.*;
import java.util.List;
public class UserDao {
private final JdbcTemplate jdbcTemplate;
public UserDao(
DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void add(User user) throws SQLException {
this.jdbcTemplate.update(
"insert into users(id, name, password) values(?, ?, ?)",
user.getId(), user.getName(), user.getPassword()
);
}
public void deleteAll(){
this.jdbcTemplate.update("delete from users");
}
public User get(String id){
return jdbcTemplate.queryForObject(
"select * from users where id = ?", (rs, rowNum) -> new User(
rs.getString("id"),
rs.getString("name"),
rs.getString("password")
), id);
}
public int getCount() {
Integer result = jdbcTemplate.queryForObject("select count(*) from users", Integer.class);
return result == null ? 0 : result;
}
public List<User> getAll() {
return this.jdbcTemplate.query(
"SELECT * FROM users ORDER BY id",
(rs, rowNum) ->
new User(rs.getString("id"), rs.getString("name"), rs.getString("password"))
);
}
}
코드가 기존에 dataSource를 가져오던 때에 비해 많이 깔끔해졌다.
하지만 그럼에도 중복되는 부분이 보인다.
(rs, rowNum) -> new User(...) 부분이다.
이 정도면 깨끗하긴 하지만, 더 깨끗한 코드를 위해서가 아니라 확장을 위해서다.
앞으로 Dao에 이렇게 Mapping 하는 코드를 더 작성할텐데, 그 때마다 이 코드를 작성해 줄 수가 없기 때문이다.
private final RowMapper<User> userRowMapper = (rs, rowNum) -> new User(
rs.getString("id"),
rs.getString("name"),
rs.getString("password"));
이렇게 Mapper 인스턴스를 만들어서 사용하자.
뭔가 함수를 변수로 가지고 있는 것 같지만
private final RowMapper<User> userRowMapperRaw = new RowMapper<>() {
@Override
public User mapRow(ResultSet rs, int rowNum) throws SQLException {
return new User(
rs.getString("id"),
rs.getString("name"),
rs.getString("password"));
}
};
그냥 이렇게 RowMapper 인터페이스를 구현해서 가지고 있는 것이다.
@FunctionalInterface
public interface RowMapper<T> {
@Nullable
T mapRow(ResultSet rs, int rowNum) throws SQLException;
}
이렇게 @FunctionalInterface를 가지고 있기 때문에 가능한 일이다.
일단 이렇게해서 템플릿에 대해 공부했다.
뭔가 JDBC가 많이 나왔지만, 그래도 최대한 템플릿과 callback으로 이해해보려고 한다.
물론 이제 userDao의 모든 메서드에서 dataSource를 통한 connection을 제거하고, userDao가 dataSource에 의존하지 않도록 만들어야 하지만, add와 deleteAll만 수정해두었다.
그럼 이 JdbcContext를 주목해보자.
현재 인터페이스를 사용하지 않고 클래스로 바로 구현하고 있다.
기존의 DI에 맞지 않는 느낌이다.
클래스 레벨에서의 의존관계가 결정되기 때문이다. 의존관계 주입의 개념에 따르면, 인터페이스를 통해 클래스 레벨에서는 의존관계가 생기지 않도록 하고, 런타임 시에 의존할 오브젝트와의 관계를 동적으로 주입해주는 것이 맞다.
그렇기에 인터페이스를 통하지 않았다면 DI라고 볼 수 없을 것이다.
이렇게 인터페이스를 통해 클래스를 자유롭게 변경할 수 있도록 하지 않았지만, 그럼에도 이렇게 만든 이유에 대해 생각해보자.
JdbcContext를 싱글톤으로 만들기 위해서다.
JdbcContext가 DI를 통해 다른 빈에 의존하고 있기 때문이다. (Datasource에 의존)
이러한 장점들 때문에 JdbcContext를 스프링 빈으로 생성한 것이다.
그리고 현재 UserDao와 JdbcContext가 길밀하게 연관되어 있다.
어차피 UserDao는 한상 JdbcContext와 함께 사용되어야 하며, UserDao에 따라 JdbcContext를 수정할 가능성도 높다.
그렇기에 굳이 인터페이스를 두지 않고 이렇게 강력한 결합을 만들어도 되는 것이다.
이런 경우에는 DI의 필요성을 통해 빈으로 등록해도 나쁘지는 않은 생각인 것이다.
스프링 빈으로 등록하지 않고 UserDao에 DI 하는 방법 대신 다른 방법도 존재한다.
UserDao 내부에서 직접 DI를 적용하는 방법이다.
public class UserDao {
private final DataSource dataSource;
private final JdbcContext jdbcContext;
public UserDao(
DataSource dataSource) {
this.dataSource = dataSource;
this.jdbcContext = new JdbcContext(dataSource);
}
}
이렇게 UserDao의 생성자에서 JdbcContext를 생성하고 가져가는 방법으로 JdbcContext를 이용할 수 있다.
하지만 이 방법도 UserDao와 JdbcContext간에 긴밀한 연결이 생긴다.
그리고 JdbcContext가 싱글톤으로 생성되지 않고 Dao마다 하나씩 생성된다는 문제가 있다.
대신 JdbcContext가 UserDao를 내부에서 만들어서 사용하기에 연결관계가 외부로 드러나지 않는다는 장점이 있다.